
What is AWS Fault Injection Simulator and why you should care.
In this blog post I will explain a little bit about distributed systems and why chaos engineering, a relatively new discipline, emerged as…

Part 1 — AWS Fault Injection Simulator series


Distributed systems
While the benefits of distributed computing are undeniable and have revolutionized IT, they do have some challenges.
Challenges with distributed systems involved latency, scalability, reliability, resilience, concurrency, designing APIs, marshaling and unmarshaling data, and the complexity of consensus algorithms such as Paxos.
As systems grow larger and more distributed, what are often only theoretical edge cases can sometimes turn into real occurrences.
While most people understand distributed systems are complex, it is common to think that this complexity only applies to applications with hundreds or thousands of micro-services. And that is, of course, not the case.
Even simple applications are complex — take, for example, a simple client-server communication. There are a lot of steps involved to complete a single round trip successfully!

1.Client puts Message onto Network.
2.Network delivers Message to Server.
3.Server validates Message.
4.Server updates its state if required.
5.Server puts Reply onto Network.
6.Network delivers Reply to Client.
7.Client validates the Reply.
8.Client updates its state if required.
It is mind boggling to consider all the permutations of failures that can happen in this simple distributed system. For example, network may go down at any time, data store may be down or overloaded, or validation logic may fail causing the application to crash.
Now imagine all that over multiple requests. And especially how it looks like for 1000s or millions of requests!
Note: Read more on the challenges of distributed systems here
The traditional way to tackle this challenge has been testing. But as distributed systems have grown more complex, testing has reached its limits. And, lets be honest here, we often only implement tests after outages. Which, naturally, is too late.
Testing is of course mandatory, and you shouldn’t stop doing it, but it doesn’t apply well for distributed systems. Testing often doesn’t address the complexity of production environments.
Testing “tests” things in isolation and often only verifies the known conditions via assertions.
Tests answer questions like:
Is it what we are expecting? Is the result of that function equal 2?
What about random failures and other weird intermittent errors that happen on networks like the Internet? How about configuration limits and configuration drifts? What about the unknown?
How can you test something you dont know about?
Some things are just really hard to test. For example, in a system where instances start and stop dynamically, what happens if any of the instances run out of disk space?
I am pretty sure the vast majority of you reading this blog post have seen disk space failures in some form or another. Debugging apps that run out of disk space look something like that:

That’s a relatively common issue that happens often when there is no log rotation on the instance.
To make things more complicated, you can get a no space left on device error when there’s plenty of space left on the device! For example, when the file system has run out of inodes because too many files have been created.
The problem with disk space failures is that they are localized, and you can’t catch them during testing.
What happens when you have a disk space failure?
If your instance does not have space left to write logs, it most of the time fails fast, and that is a real issue because by failing fast it creates a backhole.
Because it fails fast, it usually fools load balancers into thinking the instance is free to receive more requests, which in turn fail too.
If we could have caught that earlier, we could have made improvements beforehand and avoided the outage. Improvements such as:
1 — Using log rotation.
2 — Using a centralized log service.
3 — Monitoring disk space.
4 — Reviewing metrics in weekly operational meetings.
5 — Have some alarms when only 10% of disk space is left on the device.
Luckily, there is a practice that helps with this kind of unknowns — and it is, as you probably guessed, chaos engineering.
Chaos engineering
Chaos engineering is the process of:
1 — Stressing an application in test or production environments by creating disruptive events, such as server outages or API throttling.
2 — Observing how the system responds.
3 — Implementing improvements.
We do that to prove, or disprove our assumptions about our system’s capability to handle these disruptive events.
But rather than let those disruptive events happen at 3am, during the weekend, and in production environment, we create them in a controlled one, and during working hours.
It’s also very important to understand that chaos engineering is NOT about injecting faults randomly without a purpose. Chaos engineering is about injecting faults in a controlled environment through well-planned experiments to build confidence in your application and tools to withstand turbulent conditions.

To do that, you have to follow a well-defined, scientific method that will take you from understanding the steady-state of the system you are dealing with, to articulating a hypothesis, running an experiment, often using fault injection, verifying the results, and finally, learning from your experiments in order to improve the system.
It is also important to note that chaos engineering it isn’t just about improving the resilience of your application. It is also very useful to improve:
The application’s performance
Uncover hidden issues
Expose monitoring, observability & alarm blind spots
Improve recovery time
Improve operational skills
Improve the culture
Etc.
If you want to learn in more details about chaos engineering, click on the link below.
The Chaos Engineering Collection
A list of my chaos engineering blog posts.medium.com
The problem with chaos engineering
While chaos engineering is a great-to-have option in your tool box, the truth is that it is hard to get started with. Hard because, most of the time, you have to stitch different tools, scripts, and libraries together to cover the full spectrum of faults you can inject in a system. The infrastructure, the network, the applications — each target has different tools for the job, whether it´s a library, an agent, or a sidecar container to install.
Customers often don’t want to install anything extra in their applications — more things to install equal more complexity. Or, if things have to be installed, they need to be centrally managed and uniform.

It is also difficult to ensure a safe environment in which to inject faults. Ideally, you want your tools to automatically stop and roll-back if any alarms are setting off. You also want these to integrate nicely with your existing monitoring solution.
And finally, some failures are simply really hard to reproduce. It is important to realize that outages rarely happen because of one single failure. It is often a combination of small failures happening at the same time or in a sequence. And that’s just hard to reproduce.
AWS Fault Injection Simulator
To address these concerns, we have recently launched AWS Fault Injection Simulator (AWS FIS), a fully managed service for running fault injection experiments on AWS that makes it easier to improve an application’s performance, observability, and resilience.
Supported actions are listed here — but more will follow.

Easy to get started
Getting started with the service is very easy, this is something we have, and continue to put, a lot of effort into.
You can use the AWS Console to get familiar with the service — try things out. Then you can use the AWS SDK to take advantage of the templates and integrate the service with CI/CD pipeline.
The AWS FIS experiment templates are JSON or YML files that you can import, export, and share with your team. You can version control them to benefits all the best practices associated with code review.
Real-world conditions
You can run experiments in sequence or in parallel. Sequences are used to test impact of gradual degradation, like sequence of actions to gradually increase latency, and parallel experiments are to test the impact of multiple concurrent issues — which is often how real-world outages happen.
Just to hit the nail on the head here — these faults are really happening — at the service control plane level. An instance is actually terminated, memory is actually being utilized, APIs are actually being throttled. It’s not “faking it” with metric manipulation. So please, use extra caution when using the service.
Safeguards
Safeguards act as the automated stop button. A way to monitor the blast radius of the experiment and make sure that it is contained — and that failures created with the experiment are roll-backed if alarms go off, which means that the impact of the experiment was larger than the expectation.
AWS FIS integrates with IAM roles and policies so you can be sure that only authorized parties can run experiments. You can also define more fine-grained controls, for example what type of faults are authorized, and on which resources.
Using AWS FIS
You can use AWS FIS via the AWS Console or the AWS CLI. The console is great for getting started and trying things out during a GameDay, for example, while the AWS CLI lets you automate things with your CI/CD pipeline.

When you create your chaos experiment from the console, AWS FIS automatically creates a template for you — a template you can export and reuse later.
Once you start your experiment, AWS FIS injects failures, real failures, on your AWS resources.
It is a recommended best practice to have CloudWatch alarms monitoring your AWS resources and workload and define the Stop Conditions that will automatically stop the experiment if they change status.
AWS FIS Components
To use the service, you only need to understand these four components — Actions, Targets, Experiment templates, and Experiments.
Let’s take a look at each — what they do and how to define them.

1 — Actions are the fault injection actions executed during an experiment. They are define using the namespace
aws:<service-name>:<action-type>Actions include:
Fault type
Duration
Targeted resources
Timing relative to any other actions
Fault-specific parameters, such as roll-back behavior or the portion of requests to throttle

It is worth noting that some host level actions (on EC2 instances) are performed through the AWS Systems Manager Agent. The SSM Agent is Amazon software that is installed by default on most Amazon Linux and Ubuntu images. I will show you the integration in the demo below.
2 — Targets define one or more AWS resources on which to carry out an action. You define targets when you create an experiment template. You can use the same target for multiple actions in your experiment template.
Targets include:
The resource types
The resources tags and filters
The selection mode — how many of the resource to target (ALL, COUNT, PERCENT).
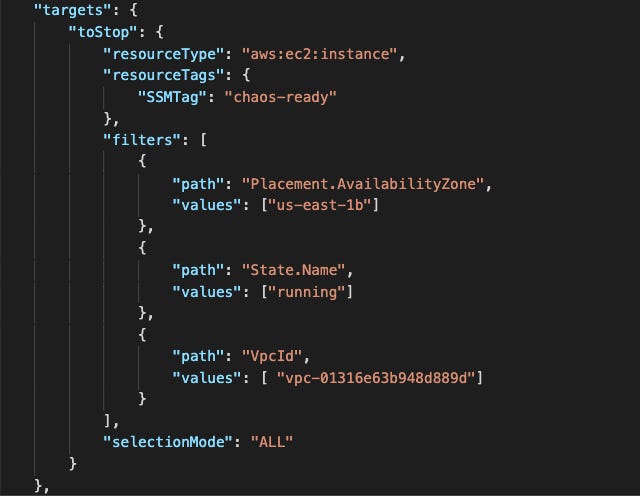
Filters are queries that identify target resources according to specific attributes. You can, for example, use filters to target running instances that are in one particular VPC and Availability Zone as shown above.
3 — Experiment templates define a complete experiment and are used in the start-experiment command.
Experiment templates include:
Actions
Targets
Stop condition alarms
IAM role
Description
Tags
AWS FIS Experiments templates
Following is a fully operating AWS FIS template that let you stop three random EC2 instances that are tagged with Purpose: chaos-ready and restart them after two minutes. The experiment then waits for three minutes, and another set of three random instances will be stopped and eventually restarted too.
If the AWS CloudWatch alarm NetworkInAbnormal sets off during the execution of the experiment, the experiment itself will be canceled and the instances restarted immediately.
Here is another experiment that will throttle the EC2 DescribeInstances and DescribeVolumes APIs on EC2 instances that are assigned the SSM-ChaosIAM role.
Executing this last AWS FIS template and testing the EC2 DescribeInstances API on EC2 instances that have the IAM Role SSM-Chaos will produce the following:
$ aws ec2 describe-instances — region us-east-1An error occurred (RequestLimitExceeded) when calling the DescribeInstances operation (reached max retries: 4): Request limit exceeded.As explained earlier, you can create simple experiments like these — sequential, and with specific targets or create more complex experiments running in a mix of sequence and parallel execution and use advanced, dynamic filtering for your targets.
4 — Experiments are simply a snapshot of the experiment template when it was first launched. It is your history of experiment execution.
It adds information on top of the snapshot:
Creation & start time
Status
Execution ID
Experiment Template ID
IAM Role ARN
To learn more about AWS FIS, I invite you to check my re:Invent talk available on YouTube — it is a deep dive with plenty of demos.
Videos:
More recently, I have talked about AWS FIS with my colleague and friend Gunnar Grosch. In that episode, I have demoed some of the API control plane fault injections.
And finally, go check the AWS samples code repository and the several blog posts already published about using AWS FIS with containers and in a CI/CD pipeline.
Sample code and experiments:
GitHub - aws-samples/aws-fault-injection-simulator-samples
This repo contains a CloudFormation (CFN) template with examples for AWS FIS. Experiment Templates for the following…github.com
Blog Posts:
Chaos Testing with AWS Fault Injection Simulator and AWS CodePipeline | Amazon Web Services
The COVID-19 pandemic has proven to be the largest stress test of our technology infrastructures in generations. A…aws.amazon.com
Increase your e-commerce website reliability using chaos engineering and AWS Fault Injection…
Customer experience is a key differentiator for retailers, and improving this experience comes through speed and…aws.amazon.com
Chaos engineering on Amazon EKS using AWS Fault Injection Simulator | Amazon Web Services
In this post, we discuss how you can use AWS Fault Injection Simulator (AWS FIS), a fully managed fault injection…aws.amazon.com
That’s it for now, folks!
Adrian
—
Subscribe to my stories here.
Join Medium for $5 — Access all of Medium + support me & others!