


Patterns for Resilient Architecture — Part 3
Preventing service failures with health checks

Preventing service failures with health checks

What are we talking about?
In part 1, I discussed how to architect resilient architectures using the principle of redundancy, which is the duplication of components of a system in order to increase the overall availability of that system.
Such a principle implies that you use a load balancer to distribute network or application requests across a number of server instances. In order to determine whether a downstream server instance is capable of handling a request successfully, the load balancer uses health checks.

Health checks gather both local and dependency information in order to determine if a server instance can successfully handle a service request. For example, a server instance might run out of database connections. When this occurs, the load balancer should not route requests to that server instance, but instead, distribute the service traffic to other available server instances.
Health checks are important because if you have a fleet of 10 server instances behind a load balancer, and one of them becomes unhealthy but still receives traffic, your service availability will drop to, at best, 90%.
Continuing the above example, if a new request hits the server instance, it will often fail fast since it can’t get a new database connection opened. And without clear handling of that error, it can easily fool the load balancer into thinking that the server instance is ready to handle more requests. This is what we call a black hole.
Unfortunately, it gets more complicated.
Imagine for a second that you have learned your lesson and implemented a health check on each server instance, testing for connectivity to the database. What happens if you have an intermittent network connectivity issue? Do you take the entire fleet of server instances out of service, or wait until the issues go away?
This is the challenge with health checks — striking the balance between failure detection and reaction — and it’s a topic we’ll explore in this post.
Server instance failure types
There are two types of failures that can impact a server instance: local or host failures, which are on the server instance itself; and dependency failures, which are the failure of critical dependencies necessary to successfully handle a request.
Host or local failures are triggered by different things: For example: hardware malfunctions such as disk failure; OS crash after upgrade/updates; security limits such as open file limits; memory leaks; and, of course, unexpected application behavior.
Dependency failures are caused by external factors. For example: the loss of connectivity to data stores such as the external distributed caching layer or the database; service broker failures (queues); invalid credentials to object storage S3; a clock not syncing with NTP servers; connectivity issues with third party providers (SMS, notifications, etc.); and other unexpected networking issues.
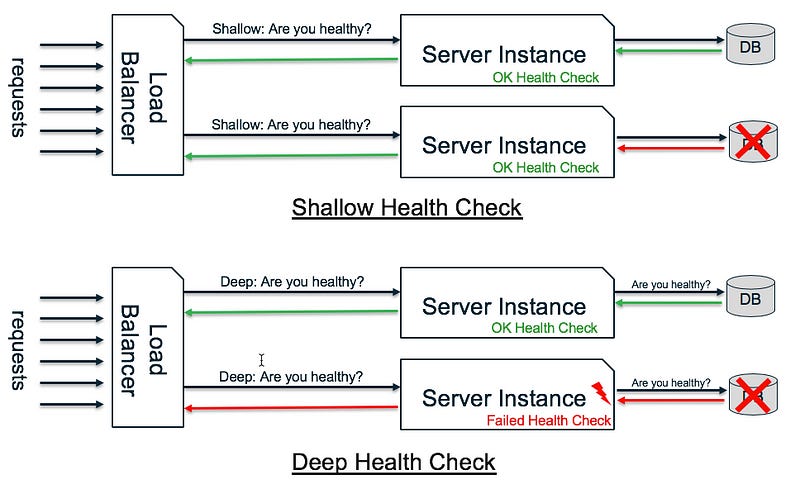
As noted above, there are plenty of reasons why a server instance might break down. The type of failures you are probing defines the type of health check you are using: a shallow health check probe for host or local failures; and a deep health check probe for dependency failures.
Shallow and Deep health checks
(1) Shallow health checks often manifest themselves as a simple ‘ping’, telling you superficial information about the capability for a server instance to be reachable. However, it doesn’t tell you much about the logical dependency of the system or whether a particular API will successfully return from that server instance.
(2) Deep health checks, on the other hand, give you a much better understanding of the health of your application since they can catch issues with dependencies. The problem with deep health checks is that they are expensive — they can take a lot of time to run; incur costs on your dependencies; and be sensitive to false-positives — when issues occur in the dependencies themselves.
Act smart, fail open!
A major issue with health checks occurs when server instances make the wrong local decision about their health — and all of the other hosts in the fleet make that same wrong decision simultaneously — causing cascading failures throughout adjacent services.
To prevent such a case, some load balancers have the ability to act smart: When individual server instances within a fleet fail health checks, the load balancer stops sending them traffic, but when server instances fail health checks at the same time, the load balancer fails open, letting traffic flow through all of them.

In AWS, there are two options to perform load balancing between resources using health checks: the AWS Elastic Load Balancers (ELB) provides health checks for resources within an AWS region; while the Route 53 DNS failover provides health checks across AWS regions. For customers not using the AWS ELB, DNS failover with Weighted Round Robin routing policies in Route 53 can provide the load balancing and failover capability.
It is worth noting that the ELBs are health checking backend EC2 instances, whereas Route 53 can health check any internet-facing endpoint in or outside of the regions while supporting several routing policies: WRR of course, but also Latency Based Routing (LBR) and Geo-location/proximity Based Routing (GBR) — and all will honor health checking.
Most importantly for our case on resilient architectures, AWS Elastic Load Balancers (both Network and Application) and Route 53 DNS failover support failing open — that is, routing requests to all targets even if no server instances report as healthy.
Such an implementation makes a deep end-to-end health check safer to implement — even one that queries the database and checks to ensure non-critical support processes are running.
Finally, if you use either Route 53 or AWS ELBs, you should always favor deep health checks over shallow ones, or use a combination of them — as together, they can more easily locate where failure happens.
A look at Route 53 health checks
Route 53 supports three different types of health checks: (1) endpoint monitoring, the most common type; (2) calculated health checks, used when you have a combination of different health checks (e.g. shallow and deep); and (3) health checks monitoring CloudWatch alarms.
Route 53 uses health checkers located around the world. Each health checker sends requests to the endpoint that you specify to determine whether the endpoint is healthy: in intervals of 30 seconds, called ‘standard’; or in intervals of 10 seconds, called ‘fast’.
Fun fact: Route 53 health checkers in different locations don’t coordinate with one another, so your monitoring system might see several requests per second regardless of the interval you chose. Don’t worry, that’s normal–randomness at work
Health checkers in every location evaluates the health of the target based on two values: (1) Response time (thus the importance of timing out explained earlier); and (2) a failure threshold, which is a number of consecutive successful (or not) requests.
Finally, the Route 53 service aggregates all the data from health checkers in different locations (8 by default) and determines whether the target is healthy.

If more than 18% of health checkers report that an endpoint is healthy, Route 53 will consider the target healthy. Similarly, if 18% or fewer health checkers report that an endpoint is healthy, Route 53 will consider the target unhealthy.

Why 18%? It’s a value that was chosen to avoid transient errors and local network conditions. AWS reserves the right to change this value in the future :)
Fun fact: 18% is not that magic but comes from the fact that most of the time there are 16 health checkers, spread over 8 regions, probing against a specific target. Since we are checking if the target is reachable from at least 3 AZ’s for us to consider it healthy— it gives you 3/16 = 18%
Last but not least, in order for Route 53 DNS failover to happen fast, DNS records should have TTLs of 60 seconds or less. This will minimize the amount of time it takes for traffic to stop being routed to the failed endpoint.
Demo: Route 53 failing open with failed health checks
To continue the example I presented in my series of blog posts on multi-region architecture, let’s take a look at route 53 failing open.
This is a reminder of the overall architecture of the multi-region backend where Route 53 is being used to serve traffic to each region while supporting failover in case one of the regions experiences issues.

I configured the Route 53 DNS failover health checks using the health API deployed here.

And I did the same for each region. You can see the routing policy between the two regional API endpoints from the API Gateway as well as the target health check.

Finally, I altered my application so that both my regional health checks are returning 400, therefore registering as unhealthy and failing.

However, as you can see, requests are still being routed to the endpoints — Route 53 is successfully failing open.

Considerations when implementing health checks:
Build a map of critical request path dependencies that are mandatory for each request, and separate operational vs non-operational dependencies. The last thing you want is your load balancing policies to be sensitive to non-critical services (e.g. failing because of the monitoring services).
When probing multiple dependencies over the network, call them concurrently if possible. This will speed up the process and prevent your deep health check from being timed-out by health checkers.
Don’t forget to timeout, degrade or even reject dependency requests if necessary, and don’t over-react — that is, don’t break at the first transient error. It is good practice to enforce an upper bound response time for each of the dependencies, and an even better practice to use a circuit breaker for all dependencies methods calls. More info can be found here.
When dependencies are failing, remember to inspect all inner exceptions of any given error in a recursive fashion since transient exceptions are often hidden by outer exceptions of different types.
Beware of the “startup” time of your deep health checks. You don’t want non-critical dependencies to prevent your newly launched server instances from being served traffic. This is especially important in situations where your system is trying to recover from outages. One solution is to probe a shallow health check during startup, and once all the dependencies are green, turn that shallow health check into a deep health check.
Make sure your server instances have reserved resources and priorities set-asides to answer to health checkers in time (remember health checkers have timeouts too). The last thing you want in production is to have your fleet of server instances to shrink down when you have a surge of traffic because your server instances failed to answer to the health check in time. This could turn into a devastating cascading failure effect through overload.
When load testing your server instances, look at understanding your max concurrent connection per instance and probe that number while health checking (remember to account for health checkers’ connections too). Often, that max concurrent connection is the limiting factor to scaling.
Oh, I almost forgot — be sure to secure your health check API endpoints!!!!!! :-)
Wrapping up
That’s it for today folks! I hope you enjoyed this post.
Please don’t hesitate to provide feedback, or share your opinions.
Part 1 — Embracing Failure at Scale
Part 2 — Avoiding Cascading Failures
Part 3 — Preventing Service Failures with Health Check
Part 4 — Caching for Resiliency
-Adrian