
Patterns for Resilient Architecture — Part 1
The story of embracing failure at scale

The story of embracing failure at scale

Part 1 — Embracing Failure at Scale
Part 2 — Avoiding Cascading Failures
Part 3 — Preventing Service Failures with Health Check
Part 4 — Caching for Resiliency
As you may know, a quote that shaped the way I think about architecture is from Werner Vogels, CTO at Amazon.com. He said:
“Failures are a given, and everything will eventually fail over time.”
Having worked on large-scale systems for more than a decade, if I could summarize in a single animation what I think about managing systems at scale and failure, it would be something like this. (this is a real video and the base jumper survived that failure)

But why? Good question Vincent!
The art of managing systems at scale lies in embracing failure and being at the edge — pushing the limits of your system and software performance ‘almost’ to breaking point, yet still being able to recover. From the outside it looks both impressive and ridiculous. That’s what resiliency is all about.
What is resiliency, and why you shouldn’t be afraid of failing.
Resilient systems embrace the idea that failures are normal, and that it’s perfectly OK to run systems in what we call partially failing mode.
When we are dealing with smaller systems of up to few tens of instances, 100% operational excellence is often the normal state and failure is an exceptional condition. However, when dealing with large-scale systems, probabilities are such that 100% operational excellence is near impossible to achieve. Therefore, the normal state of operation is partial failure.
While not suitable for life-critical applications, running in partially failing mode is a viable option for most web applications, from e-commerce services like Amazon.com to video-on-demand sites such as Netflix, to music services like Soundcloud (shameless plug to my playlists).
Of course, I’m not saying it doesn’t matter if your system fails. It does, and it might result in lost revenue, but it’s probably not life-critical.
This is the balance you should aim for: the cost of being highly resilient to failure versus the potential loss of money due to outages.
For me, building resilient architectures has been an amazing engineering journey, with ups-and-downs, some 1am wake-up calls, some Christmases spent debugging, some “I’m done, I quit” … but most of all, it’s been a learning experience that brought me to where I am today — and for that, I am forever grateful to Pagerduty :-)
This blog post is a collection of tips and tricks that have served me well throughout my journey, and I hope they will serve you well too.
It’s not all about software.
One important thing to realize early on, is that building resilient architecture isn’t all about software. It starts at the infrastructure layer, progresses to the network and data, influences application design and extends to people and culture.
The following is a list of patterns that may help you build resilient architectures, so feel free to comment and share your own experiences below.
Redundancy
One of the first things — and also one of the most important things — to do when you deploy an application in the cloud is to architect your application to be redundant. Simply put, redundancy is the duplication of components of a system in order to increase the overall availability of that system.
In the AWS cloud, that means deploying it across multiple availability zones (multi-AZ) or, in some cases, across multi-regions.

While I discussed availability in one of my previous blog posts, it is worth remembering the mathematics behind this pattern.

As you can see in the previous picture, if you take component X with 99% availability (which is pretty bad by today’s standards), but put it in parallel, you increase your overall system availability to 99.99%!!! That’s right — simply by putting it in parallel. Now, if you put three component X’s in parallel, you get to the famous 6-nines! That is just ridiculous in terms of availability, and why AWS always advises customers to deploy their applications across multi-AZ — preferably three of them (to avoid overload).
This is also why using AWS regional services like S3, DynamoDB, SQS, Kinesis, Lambda or ELB just to name a few, is a good idea — they are, by default, using multiple AZs under the hood. And this is also why using RDS configured in multi-AZ deployment is neat!
To be able to design your architecture across multi-AZ, you must have a stateless application and potentially use an elastic load balancer to distribute requests to the application.
It is important to note that not all requests have to be stateless, since in some cases we want to maintain ‘stickiness’ — but a vast majority of them can and should be, otherwise you will end up with balancing issues.
If you are interested in building multi-region redundancy, I have posted a series of posts on the topic here.
Auto scaling
Once you have the multi-AZ capability sorted out, you need to enable Auto Scaling. Auto scaling means that your applications can automatically adjust capacity to demand.

Scaling your resources dynamically according to demand — as opposed to doing it manually — ensures your service can meet a variety of traffic patterns without anyone needing to plan for it.
Instances, containers, and functions all provide mechanisms for auto scaling either as a feature of the service itself, or as a support mechanism.
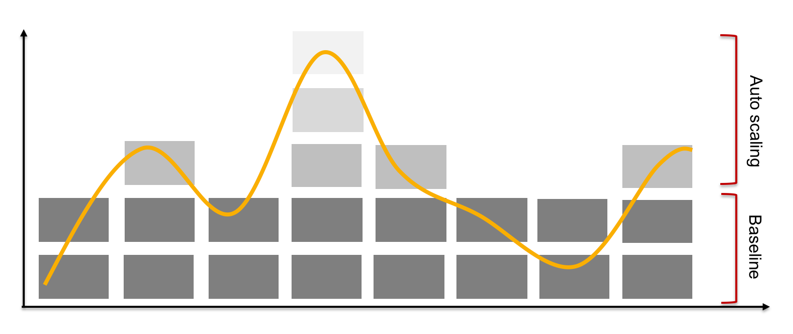
Until recently, auto scaling in AWS was linked to AWS services — but now, Application Auto Scaling can be used to add auto scaling capabilities to any services you build on AWS. That’s a big deal!!!
This feature allows the same auto scaling engine that powers services like EC2, DynamoDB, and EMR to power auto scaling in a service outside of AWS. Netflix is already leveraging this capability to scale its Titus container management platform.
Considerations for auto scaling:
The speed at which you can tolerate auto scaling will define what technology you should use. Let me explain:
I started using auto scaling with EC2 like most early adopters (back then, there wasn’t a choice). One of the first mistakes I made was to launch a new instance and have scripts (bash, puppet, or chef) do the software configuration whenever a new instance launched. Needless to say, it was very slow to scale and extremely error prone.
Creating custom AMIs that are pre-configured (known as Golden AMIs) enabled me to shift the heavy configuration setup from the instance launch to an earlier, ‘baking’ time — built within the CI/CD pipeline.
It is often difficult to find the right balance between what is baked into an AMI and what is done at scaling time. In some cases, particularly if you’re smart with service discovery, you don’t have to run or configure anything at startup time. In my opinion, this should be the goal because the less you have to do at startup time, the faster your scaling will be. In addition to being faster at scaling, the more scripts and configurations you run at startup time, the greater the chance that something will go wrong.
Finally, what became the holy grail of the Golden AMI was to get rid of the configuration scripts and replace them with Dockerfiles instead. That way, we didn’t have to maintain chef or puppet recipes — which at scale were impossible to manage — but more importantly, we could test the applications from the laptop all the way to production systems — using the same container — and do so quickly.
Today, scaling with container platforms like ECS or Lambda functions is even faster, and should be reflected in any architectural design. Large scale systems often have a combination of all these technologies.
Infrastructure as Code
One benefit of using infrastructure as code is repeatability. Let’s examine the task of configuring a datacenter, from configuring the networking and security to the deployment of applications. Consider for a moment the amount of work that would be required if you had to do that manually, for multiple environments in each of these regions. First it would be a tedious task, but it would most likely introduce configuration differences and drifts over time. Humans aren’t great at undertaking repetitive, manual tasks with 100% accuracy, but machines are. Give the same template to a computer and it will execute that template 10,000 times exactly the same way.
Now, imagine your environment being compromised, suffering an outage, or even being deleted by mistake (yes, I saw that happen once). You have data backup. You have the infrastructure templates. All you have to do is re-run the template in a new AWS account, a new VPC or even a new region, restore the backups, and voilà, you’re up-and-running in minutes. Doing that manually, and at scale, will result in a nightmare scenario, with a lot of sweat and tears — and worse: unhappy customers.
Another benefit of infrastructure as code is knowledge sharing. Indeed, if you version control your infrastructure, you can treat code the same way you treat application code. You can have teams committing code to it, and ask for improvements or changes in configuration. If that process goes through a pull-request, then the rest of the team can verify, challenge, and comment on that request — promoting better practices.
Another advantage is history preservation of the infrastructure evolution — and being able to answer “Why did we change that?” two months later.
Immutable Infrastructure
The principle of immutable infrastructure is fairly simple: Immutable components are replaced for every deployment, rather than being updated in place.
No updates should ever be performed on live systems
You always start from a new instance of the resource being provisioned: EC2 instance, Container, or a Lambda Function.
This deployment strategy supports the principle of Golden AMI and is based on the Immutable Server pattern which I love since it reduces configuration drift and ensures deployments are repeatable anywhere from source.
A typical immutable infrastructure update goes as follows:
To support application deployment in an immutable infrastructure, you should preferably use canary deployment, which is a technique used to reduce the risk of failure when new versions of applications enter production, by gradually rolling out the change to a small subset of users and then slowly rolling it out to the entire infrastructure and making it available to everybody.
According to Kat Eschner, the origin of the name canary deployment comes from an old British mining tradition where miners used canaries to detect carbon monoxide and toxic gases in coal mines. To make sure mines were safe to enter, miners would send canaries in first, and if the canary died or got ill, the mine was evacuated.

The benefit of canary deployment is, of course, the near immediate rollback it gives you — but more importantly, you get fast and safer deployments with real production test data!
There are few considerations to keep in mind during canary deployment:
Being stateless: You should preferably not be dependent on any state between the different old and new versions deployed. If you need stickiness, keep it to the bare minimum.
Since fast rollback is a feature, your application should be able to handle it gracefully.
Managing canary deployment with database schema changes is hard — really hard. I often get asked how to do it. Unfortunately there’s no silver bullet. It depends on the changes, the application, and the architecture around the database.
Canary deployment using Route53 isn’t the only option. If you use auto scaling groups behind a load-balancer you can also use a red/black deployment. The approach of reusing the load-balancer helps avoid any DNS record set changes in Route53. It goes as follows:
For your serverless applications, you also have the option of using Amazon API Gateway since it now supports canary release deployments or you can implement canary deployments of AWS Lambda functions with alias traffic shifting. Following is an example that points an alias to two different Lambda function versions by configuring an alias to shift traffic between two function versions based on weights.
To experiment with canary deployment using AWS Lambda, here is a GitHub repository that will get you started.
Stateless application
As mentioned earlier, stateless applications are a prerequisite to auto scaling and immutable infrastructure since any request can be handled by available computing resources, regardless if that’s EC2, a container platform, or a set of lambda functions.

In a stateless service, the application must treat all client requests independently of prior requests or sessions, and should never store any information on local disks or memory.
Sharing state with any resources within the auto scaling group should be conducted using in-memory object caching systems such as Memcached, Redis, EVCache, or distributed databases like Cassandra or DynamoDB, depending on the structure of your object and requirements in terms of performances.
Putting it all together!
In order to have a resilient, reliable, auditable, repeatable, and well tested deployment and scaling process with a fast spin-up time, you’ll need to combine the idea of Golden AMI, infrastructure as code, immutable infrastructure and stateless application. And, to do that at scale, you’ll have to use automation. In fact, it’s your only option. So, my last advice for that post is: Automate! Automate! Automate!
That’s all for this part folks. I hope you have enjoyed this part 1.
Please do not hesitate to give feedback, share your own opinion or simply clap your hands. In the next part, I will go on and discuss more on the patterns to avoid cascading failures. Stay tuned!
Part 1 — Embracing Failure at Scale
Part 2 — Avoiding Cascading Failures
Part 3 — Preventing Service Failures with Health Check
Part 4 — Caching for Resiliency
-Adrian