

Reliability, consistency and confidence through immutability

I’d like to express my gratitude to my colleagues and friends Ricardo Sueiras, Danilo Poccia, and Matt Fitzgerald for their valuable feedback and for being awesome.

Immutable:
not capable of or susceptible to change
Problems with immutability, or the lack thereof, isn’t a new thing. It has been around for as long as there have been programming languages.
For example, any Python developer knows that the mutable and immutable data types in Python are causing a lot of headaches — even to advanced developers. Consider this example:
>>> foo = ['hello']
>>> print(foo)
['hello']
>>> bar = foo
>>> bar += ['world']
>>> print(foo)
['hello', 'world'] <-- WHAT IS HAPPENING?What is happening? Because foo was never modified directly, but bar was, anyone would expect the following:
>>> print(foo)
['hello'] <-- WHY IS THIS NOT HAPPENING?But that isn’t happening, and that is mutability at work.
In Python, if you assign a variable to another variable of a mutable data type, any changes are reflected by both variables. In this example bar = foo.
The new variable bar is just an alias for foo.
Put simply, mutable means ‘can change’ and immutable means ’cannot change.’
Languages such as Rust, Erlang, Scala, Haskell, and Clojure offer immutable data structures and single assignment variables with the premise that immutability leads to better code, simpler to understand, and easier to maintain.
That’s all beautiful, Adrian, but what does it have to do with software architectures?
Headaches… and no one likes headaches.
The immutable infrastructure paradigm comes from the same ideas behind immutability in programming languages — your architecture doesn’t change once deployed, and it saves you from headaches.
Let’s dive into it!
Once upon an (Up)time
Uptime, according to Wikipedia, “is a measure of system reliability, expressed as the percentage of time a machine, typically a computer, has been working and available. Uptime is the opposite of downtime.”
Not so long ago, it was common for folks to brag about uptime.
The problem, though, is that long periods of uptime often indicates potentially lethal problems because critical updates, either software or hardware, often require rebooting.
Let me ask you this simple question — which of the below makes you more anxious?
(1) Rebooting a server that’s been up for 16 years.
(2) Rebooting a server that’s just been built.
That’s right, me too. Just writing it gives me anxiety. But why?
I have no idea what has changed in the 16 years since its initial boot up!
How many undocumented hotfix were done? Why was it never rebooted? Are there some hidden and magic dependencies?
To me, that’s terrifying.
Old servers can become time-bombs. We start with a hotfix on a Friday night before the weekend.
We say: “Just a quick edit to the config file to save the weekend.”
We promise: “I will document and automate the fix first thing Monday morning.”
But we never do.
One hotfix after the other, and we end up with a dangerous drifting time-bomb ready to blow up our production environment.
Traditional infrastructures
In a traditional IT infrastructure, servers are typically updated and modified in place — SSH-ing into servers and installing, updating or upgrading packages, tweaking, and optimizing configuration files. All these were, and often still are, standard practices. Less common practice, though, is to document all these changes.
These practices make servers mutable; they change after they are created.
Besides giving you headaches, mutations also lead to configuration drifts, which happens when active configurations diverge from the initially approved and deployed configuration.
One of the main challenges with configuration drifts is that they make it hard to “just replace” or debug things — making recovering from issues difficult.
Configuration drifts often were, and still are, a consequence of low automation and manual processes. Back then, deployment tools were generally expensive and not as available as they are today. They required deep expertise, and thus automation wasn’t a priority.
Don’t fear what you know about your architecture; fear what you don’t know!
Remember that failures happen all the time, so one of the most important things you can optimize is your recovery time from failures — or MTTR.
“Failures are a given, and everything will eventually fail over time.” — Werner Vogels, CTO at Amazon.
Moreover, if your tests and validations occur in an environment in which configurations don’t match those of your production environment, well, it’s useless.
Mutable deployments
Another common practice in traditional infrastructure is mutable deployments. Meaning the deployment pipeline gets the code, fetches the dependency, builds the artifacts, and deploys them for every environment stage of the deployment pipeline. One build per environment.
What you test and validate isn’t what you deploy!
I’ve seen places where deploying to production meant first launching any instance (“any” since it wasn’t the same between environments), fetching the code from GitHub, building it, replacing the artifacts in-place — and finally — rebooting the server. One step was missing, though — pray.
I’m sure you are all either smiling or are horrified by the idea — but think about the following:
How many of your applications fetch dependencies from the internet during the build process, or worse, at runtime?
How about:
>>> pip install -r requirements.txt>>> npm install>>> docker buildWhat guarantees do you have that the dependencies you are installing don’t change between deployments? And what if you are deploying to multiple machines or environments?
Don’t you believe me?
Read “How one programmer broke the internet by deleting a tiny piece of code” (with the bonus discussion) or “To fight ‘evil’ ICE, an engineer pulled his code off GitHub.”
Again, what you test and validate isn’t what you deploy!
Or worse:
What happens if your code repository (e.g., GitHub or GitLab) has issues when you deploy, and you can’t download your code when you need it?
Finally, installing dependencies at runtime is also an attack vector for malicious code injection and it renders auto-scaling slow (more on this below).
That deployment behavior is fragile at best and leads to deployment mistakes and frequent rollbacks. And that’s if you’re lucky.
Luckily, there’s a solution!

Immutable infrastructure
Put simply, immutable infrastructure is a model in which no updates, security patches, or configuration changes happen “in-place” on production systems. If any change is needed, a new version of the architecture is built and deployed into production.
The most common implementation of the immutable infrastructure paradigm is the immutable server. It means that if a server needs an update or a fix, new servers are deployed instead of updating the ones already used. So, instead of logging in via SSH into the server and updating the software version, every change in the application starts with a software push to the code repository, e.g., git push. Since changes aren’t allowed in immutable infrastructure, you can be sure about the state of the deployed system.
Deploying applications in immutable infrastructures should use the canary deployment pattern. Canary deployment is a technique used to reduce the risk of failure when new versions of applications enter production by creating a new environment with the latest version of the software. You then gradually roll out the change to a small subset of users, slowly making it available to everybody if no deployment errors are detected.
Immutable infrastructures are more consistent, reliable, and predictable; and they simplify many aspects of software development and operations by preventing common issues related to mutability.
The term “immutable infrastructure” was coined by Chad Fowler in his blog post “Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components,” published in 2013. Since then, the idea has — rightly so — gained popularity and followers , especially as systems have become more complex and distributed.
Some of the benefits include:
(1) Reduction in configuration drifts — By frequently replacing servers from a base, known and version-controlled configuration, the infrastructure is reset to a known state, avoiding configuration drifts. All configuration changes start with a verified and documented configuration push to the code repository, e.g., git push. Since no changes are allowed on deployed serves, you can remove SSH access permanently. That prevents manual and undocumented hotfixes, resulting in complicated or hard-to-reproduce setups, which often lead to downtime.
(2) Simplified deployments — Deployments are simplified because they don’t need to support upgrade scenarios. Upgrades are just new deployments. Of course, system upgrades in immutable infrastructure are slightly slower since any change requires a full redeploy. The key here is pipeline automation!
(3) Reliable atomic deployments — Deployments either complete successfully, or nothing changes. It renders the deployment process more reliable and trustworthy, with no in-between states. Plus, it’s easier to comprehend.
(4) Safer deployments with fast rollback and recovery processes — Deployments using canary patterns are safer because the previous working version isn’t changed. You can rollback to it if deployment errors are detected. Additionally, since the same process to deploy the new version is used to rollback to older versions, it makes the deployment process safer.
(5) Consistent testing and debugging environments — Since all servers running a particular application use the same image, there are no differences between environments. One build deployed to multiple environments. It prevents inconsistent environments and simplifies testing and debugging.

(6) Increased scalability — Since servers use the same base image, they are consistent and repeatable. It makes auto-scaling trivial to implement, significantly increasing your capacity to scale on-demand.
(7) Simplified toolchain — The toolchain is simplified since you can get rid of configuration management tools managing production software upgrades. No extra tools or agents on servers. Changes are made to the base image, tested, and rolled-out.
(8) Increased security — By denying all changes to servers, you can disable SSH and remove Shell access to servers. That reduces the attack vector for bad actors, improving your organization’s security posture.
The immutable server
Let’s take a look at an essential aspect of immutable infrastructure — the immutable server.
An immutable server, or golden image, is a standardized template for your application server.
Typically, the golden image starts from a base image from which you remove unnecessary packages, harden it and apply security patches. Often it also includes agents for monitoring and tools for shipping logs out of the instance, does security audits, and performance analysis.

Using golden images ensures you have consistent, reviewed, tested, and approved images for use within your organization.
As you identify potential new vulnerabilities in the software, you can update the golden image with the appropriate security patches, test the image, and deploy the newly created golden image to your environment.
Manually updating golden images is time-consuming and error-prone. Therefore, you should automate the creation of golden images with open source tools like Packer, Netflix Animator, or AWS tools such as EC2 Image Builder.
Once automated, you can build standardized and repeatable processes to:
Continuously assess active golden images for security posture vulnerabilities.
Decommission obsolete or insecure golden images as new vulnerabilities are discovered.
Distribute golden images to different parts of the organization and enforce consistent policies in heterogeneous environments.
These processes help improve the operation and security posture of organizations by limiting the attack surface of bad actors and mitigating risk.
Building golden images with EC2 Image Builder
EC2 Image Builder simplifies the creation, maintenance, validation, sharing, and deployment of both Linux and Windows Server images on EC2 or on-premises. It provides built-in automation, validation, and AWS-provided security settings for keeping images up-to-date and secure. It also enables version-control of your images for easy revision management. In other words, it is perfect for building golden images as it simplifies many of the manual processes required.

Considerations when building and using golden images
(1) Include as many dependencies as possible in your golden images. It will give you the most confidence that the image tested is what is deployed to production. It will also improve the scalability of your application (more on scalability below).
(2) Some configurations need to occur at the application start time. Consider service discovery mechanisms to help, or simply build a mechanism around the AWS metadata URI.
Connect to AWS EC2 metadata URI
(http://169.254.169.254/latest/dynamic/)and get the instanceID. From the instanceID, query the instance tags, e.g “config location”, and get the configuration from the value of the tag.
For more information on using the metadata URI, check out this brilliant session from re:Invent 2016, Life Without SSH.
(3) Since immutable servers mean you can’t update system configuration in place and need to redeploy to apply changes to the configuration, consider decoupling physical server addresses from their roles. Using Amazon Route 53 with a private hosted zone and DNS within Amazon VPC is perfect for that.
(4) Building a stateless application is mandatory since any server can get terminated and rebuilt, and it should happen without any loss of data. If you need stickiness, keep it to the bare minimum. In a stateless service, the application must treat all client requests independently of prior requests or sessions and should never store any information on local disks or memory. Sharing state with resources in an auto-scaling group should be done using in-memory object caching systems such as Memcached, Redis, or EVCache, or distributed databases like Cassandra or DynamoDB, depending on the structure of your object and requirements in terms of performance. You can also use a shared file system such as Amazon EFS, a fully managed elastic NFS file system.
(5) On EC2 instances, always opt for mountable storage devices like Amazon EBS volumes, which can be attached to new servers when old ones are terminated. You can use EBS Snapshots with automated lifecycle policies to back up your volumes in Amazon S3, ensuring the geographic protection of your data and business continuity. EBS Snapshots can also be attached quickly to forensic EC2 instances if necessary.
Note: At the application design phase, make sure you separate ephemeral from persistent data and ensure you are persisting only the data you need so that you can avoid unnecessary costs. It also dramatically simplifies operations.
(6) Ship logfiles off EC2 instances and send them to a central log server. Logstash, ElasticSearch, and Kibana are tools widely used for this purpose. The ELK stack is also available as a managed AWS service.
Scalability considerations
The speed at which you can tolerate auto-scaling will define what technology you should use. Let me explain:
I started using auto-scaling with EC2 like most early adopters. The first mistake I made was to launch new instances with initialization scripts to do the software configuration whenever a new instance launched. It was very slow to scale and extremely error-prone.
Creating golden images enabled me to shift the configuration setup from the instance launch to an earlier ‘baking’ time built within the CI/CD pipeline.
It is often difficult to find the right balance between what you bake into an image and what you do at scaling time. If you’re smart with service discovery, you shouldn’t have to run or configure anything at startup time. It should be the goal because the less you have to do at startup time, the faster your application will scale up. In addition to being faster at scaling up, the more scripts and configurations you run at initialization time, the higher the chance that something will go wrong.
Finally, what became the holy grail of golden image was to get rid of the configuration scripts and replace them with Dockerfiles. Testing became a lot easier as the container running the applications was the same, from the developer’s laptop to production.
Immutability, Containers, and Bottlerocket
It is safe to say that containers have today become the standard method to package and run applications. Yet, similarly to applications running on EC2 instances, applications running on containers are prone to the same issues : updating, drift, overhead, and security.
To address these problems, in March 2020, AWS announced the launch of Bottlerocket, an open-source operating system for running containers on both virtual machines and bare-metal hosts.
Bottlerocket reflects much of what we have discussed so far:
First, it includes only the software essential to running containers, which significantly reduces the attack surface compared to general-purpose operating systems.
Also, it uses a primarily read-only file system that is integrity-checked at boot time via dm-verity. SSH access is discouraged and is available only as part of a separate admin container that you can enable on an as-needed basis for troubleshooting purposes.
Bottlerocket doesn’t have a package manager, and updates are applied and can be rolled back in a single atomic action, reducing potential update errors. It has built-in integrations with AWS services for container orchestration, registries, and observability, making it easy to start with and deploy.
Finally, Bottlerocket supports Docker image and images that conform to the Open Container Initiative (OCI) image format.
In summary, Bottlerocket is a minimal OS with an atomic update and rollback mechanism which gives limited SSH access. In other words, it’s a perfect fit for our immutable infrastructure model.
Security considerations
NO KEYS on server = better security!
SSH turned OFF = better security!
The beauty of immutable infrastructure is that it not only solves many of the issues discussed thus far, but it also transforms security. Let me explain.
Mutability is one of the most critical attack vectors for cyber crimes.
When a bad actor attacks a host, most of the time it will try to modify servers in some way — for example, changing configuration files, opening network ports, replacing binaries, modifying libraries, or injecting new code.
While detecting such attacks is essential, preventing them is much more important.
In a mutable system, how do you guarantee that changes performed to a server are legitimate or not? Once a bad actor has the credentials, you simply can’t know any more.
The best strategy you can leverage is immutability, and simply deny __all__ changes to the server.
A change means the server is compromised, and it should either be quarantined, stopped, or terminated immediately.
That is is DevSecOps at its best! Detect. Nuke. Replace.
Extended the idea to cloud operations; the immutability paradigm lets you monitor any unauthorized changes happening in the infrastructure.
Doing this on AWS Cloud means detecting changes using AWS CloudTrail and AWS Config, alerting via SNS, remediating with AWS Lambda, and replacing with AWS CloudFormation.
There are also plenty of third party tools that specialize in this: e.g., Capsule8 and TrendMicro.
Finally, remember:
“Your goal is to raise the cost of attacks, ideally beginning at design” — Controlled chaos: The inevitable marriage of DevOps and security, Kelly Shortridge.
It is the future for security in the cloud, and you should embrace it now.
Immutable deployment pattern
To support application deployment in immutable infrastructure, you should use an immutable deployment pattern. My favorite is the canary deployment. This is a technique used to reduce the risk of failure when new versions of applications enter production, by gradually rolling out the change to a small subset of users and then slowly rolling it out to the entire infrastructure and making it available to everybody. Canary deployment is sometimes called a phased or incremental rollout.
According to Kat Eschner, the origin of the name canary deployment comes from an old British mining tradition where miners used canaries to detect carbon monoxide and toxic gases in coal mines. To ensure mines were safe to enter, miners would send in canaries first, and if the canary died or got ill, the miners would evacuate.
Using canary deployment, you deploy a new version of the application progressively, by increments, starting with a few users. If no errors are detected, the latest version can gradually roll out to the rest of the users. Once the new version is deployed to all users, you can slowly decommission the old version. This strategy minimizes the potential blast-radius of failure, limiting the impact on customers. It is, therefore, preferred.
The benefit of canary deployment is, of course, the near-immediate rollback it gives you — but more importantly, you get fast and safer deployments with real production test data.
The main challenge with canary deployment is routing traffic to multiple versions of the application. Consider several routing or partitioning mechanisms:
Internal teams vs. customers
Paying customers vs. non-paying customers
Geographic-based routing
Feature flags (FeatureToggle)
Random**
** By keeping canary traffic selection random, most users aren’t adversely affected at any time by potential bugs in the new version, and no single user is adversely affected all the time.
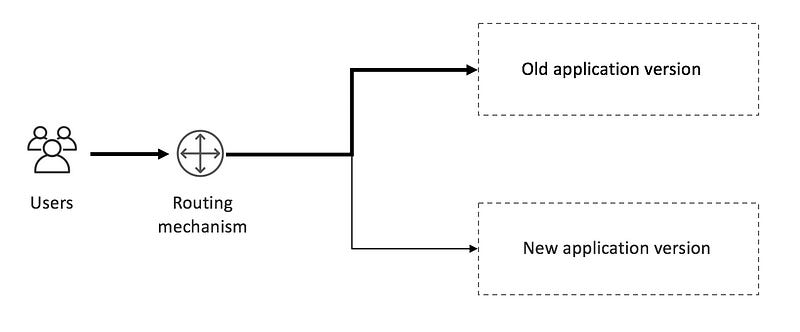
Considerations for canary deployments:
For every incremental change in traffic distribution, make sure you carefully monitor for errors in the logs and changes in the steady-state.
Be pessimistic about your deployments; assume deployments have failed unless you receive positive confirmation.
If you notice any problems or don’t get confirmation of a successful deployment, rollback immediately and investigate thereafter.
Wait a sufficient amount of time between each increment. The amount of time depends on the application. Use good judgment.
If no error is detected, you can proceed to increase the weight distribution incrementally. Apply a 10% incremental change at a time maximum. Again, use good judgment.
Wait before decommissioning older versions of the software. You never know when you will have to rollback. Sometimes it can be hours or days after deploying the new version.
Canary deployments with database schema changes are hard. There’s no silver bullet — it depends on the changes, the application, and the overall system design. That is a good reason to evaluate using schema-less NoSQL databases.
Canary deployments on AWS
(1) Using Route 53 with weighted routing policy
Route 53 lets you use a weighted routing policy to split the traffic between the old and the new version of the software you are deploying. Weighted routing enables you to associate multiple resources with a single domain name or subdomain name and choose how much traffic is routed to each resource. It is particularly useful for canary deployments.
To configure weighted routing for canary deployment, you assign each record a relative weight that corresponds with how much traffic you want to send to each resource. Route 53 sends traffic to a resource based on the weight that you assign to the record as a proportion of the total weight for all records.
For example, if you want to send a tiny portion of the traffic to one resource and the rest to another resource, you might specify weights of 1 and 255. The resource with a weight of 1 gets 1/256th of the traffic (1/1+255), and the other resource gets 255/256ths (255/1+255).
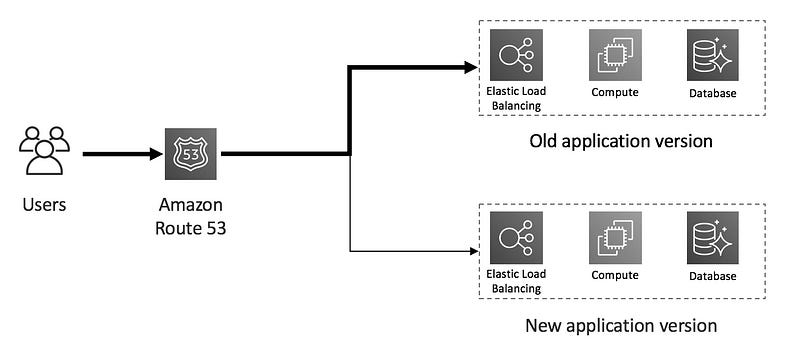
This is my favorite implementation of canary deployment as the traffic split starts from the very top of the architecture — DNS. To me, it is easier to understand and to implement.
If there’s one inconvenience to using DNS, it’s propagation time. From the Route 53 FAQs:
Amazon Route 53 is designed to propagate updates you make to your DNS records to its worldwide network of authoritative DNS servers within 60 seconds under normal conditions. A global change is successful when the API call returns an INSYNC status listing.
Note that caching DNS resolvers are outside the control of the Amazon Route 53 service and will cache your resource record sets according to their time to live (TTL). The INSYNC or PENDING status of a change refers only to the state of Route 53’s authoritative DNS servers.
So, watch out for the default TTL values, and shorten them.
(2) Using multiple Auto-Scaling groups (ASG)
For this method, you need various ASGs behind a Load Balancer. You can then update one of the ASG with the new golden image — incorporating the latest version of the software — and replace the current instance with the new one using rolling-updates. Rolling-updates launch the new instance first. Once “healthy” with the load balancer, it drains the connections with the old instances and terminates them progressively. It is, therefore, a safe deployment method, and with no downtime.
For example, if your application needs a minimum of seven instances to run smoothly, you can use one ASG with six instances (two per AZ), and a second ASG with only one instance. You can then update the instance in the second ASG with the latest golden image. It becomes your canary, with 1/7th of the traffic.
You can then slowly increase the number of instances in that second group and progressively reduce the number of instances in the first ASG. In that case, your increment is roughly 14%. Naturally, the larger the number of instances in the first ASGs, the smaller the increment. Rolling back is straightforward; simply increase the maximum number of instances in the first ASG and remove the second ASG, or update it with the old image.
This method is easy to automate since CloudFormation supports the UpdatePolicy attribute for ASGs with AutoScalingRollingUpdate policy.
Note:
Both the strategies mentioned above can cause delays due to DNS TTL caching or ASG updates and introduce additional costs. Fortunately, AWS recently announced weighted target groups for application load balancers, which lets developers control the traffic distribution between multiple versions of their application.
(3) Using Application Load Balancer and Weighted Target Groups
When creating an Application Load Balancer (ALB), you create one or more listeners and configure listener rules to direct the traffic to one target group. A target group tells a load balancer where to direct traffic to, e.g., EC2 instances, Lambda functions, etc.
To do canary deployment with the ALB, you can use forward actions to route requests to one or more target groups. If you specify multiple target groups for forward action, you must specify a weight for each target group.
Each target group’s weight is a value from 0 to 999. Requests that match a listener rule with weighted target groups are distributed to these target groups based on their weights. For example, if you specify two target groups, one with a weight of 10 and the other with a weight of 100, the target group with a weight of 100 receives ten times more requests as the other target group.
If you require session stickiness, you can enable target group stickiness for a particular rule. When the ALB received the first request, it generates a cookie named AWSALBTG that encodes information about the selected target group, encrypts the cookie, and includes the cookie in the response to the client. To enable stickiness, the client needs to add that cookie in subsequent requests to the ALB.
To learn more about using Weighted Target Groups with the Application Load Balancer, please read this excellent blog post by my colleague Sébastien Stormacq.
What about serverless applications?
Similar to standard applications, with serverless, you need to take a conservative and pessimistic approach to deployment. So, instead of completely replacing the APIs or Lambda function with a new version, you need to make the new version coexist** with the old stable one and validate its performance and robustness gradually during the deployment. You need to split the traffic between two different versions of your APIs or functions.
** Decommission obsolete or insecure Lambda functions as new vulnerabilities are discovered.
(4) Using API Gateway release deployments
For your serverless applications, you have the option of using Amazon API Gateway since it supports canary release deployments.
Using canaries, you can set the percentage of API requests that are handled by new API deployments to a stage. When canary settings are enabled for a stage, API Gateway will generate a new CloudWatch Logs group and CloudWatch metrics for the requests handled by the canary deployment API. You can use these metrics to monitor the performance and errors of the new API and react to them. You can then gradually increase the percentage of requests handled by the new API deployment, or rollback if errors are detected.
Please note that currently, API Gateway canary deployment only works for REST APIs, not the new HTTP APIs.
(5) Using AWS Lambda alias traffic shifting
With alias traffic shifting you can implement canary deployments of Lambda functions. Simply update the version weights on a particular alias, and the traffic will be routed to new function versions based on the specified weight. You can easily monitor the health of that new version using CloudWatch metrics for that alias and rollback if errors are detected.
For more detail on canary deployments with AWS Lambda alias traffic shifting, please read this great post by Chris Munns.
Changing aliases’ weights and checking the behavior of the newly deployed functions should, of course, be automated. Fortunately, AWS CodeDeploy can help as it can automatically update function alias weights based on a predefined set of preferences and automatically rollback if needed.
To start using AWS Lambda alias traffic shifting with CodeDeploy in just a few lines of code, check out the AWS SAM integration or the serverless.com framework one.
Out of the box, both give you:
Automatic alias creation.
Gradual shifting of traffic with rollback if needed.
Pre-traffic and post-traffic test functions to verify the deployment is successful.
CloudWatch alarm integration.
(6) Automating deployments with AWS CodeDeploy
You can use AWS CodeDeploy to automate your canary deployments, whether it is on Amazon EC2, Amazon ECS, AWS Fargate, AWS Lambda, and even for on-premises servers. Read more here.
Immutable infrastructure readiness checklist
Here is a shortlist to help you make sure you are ready with immutable infrastructure.
☑ Infrastructure as code
☑ Outstanding monitoring for applications and deployments
☑ Centralize logging
☑ Tracing
☑ Deployment automation using immutable deployment pattern (canary)
☑ Golden image creation and update pipeline
☑ Processes to assess, decommission, and distribute golden images
☑ Stateless applications layer
☑ Beware of temporary, transient state
☑ Using snapshot for volumes
☑ Using databases, object or in-memory data-stores for data
☑ SSH turned off
☑ No SSH keys on servers
What’s next?
If you like the idea of immutability, reducing vulnerability surface area, increasing the speed of deployment, and minimizing configuration drift, you’ll probably love unikernels.
Unikernels
The idea of using unikernels in the cloud isn’t new. It was first introduced by Anil Madhavapeddy in 2013: Unikernels: Library Operating Systems for the Cloud — (Madhavapeddy et al., 2013)
“Unikernels are specialized, single-address-space machine images constructed by using library operating systems.” (Unikernel.org)
Unikernels are restructured VMs, designed to have components that are more modular, flexible, secure, and reusable, built in the style of a library OS. They are specialized OS kernels written in a high-level language and act as individual software components. A full application may consists of multiple running unikernels working together as a distributed system.
The most exciting part is that unikernels compile application code together with the operating system, without the thousands of unnecessary drivers OS usually included. The compiled image is minimalist.
The main benefits are:
(1) Fast startup time: Since unikernels are minimalist and lightweight, they boot extremely fast, within milliseconds.
(2) Improved security: Since unikernels only compile what it needs, the number of drivers and configuration code deployed is reduced, which in turn minimizes the attack surface, thus improving security.
(3) Less prone to configuration drifts: Since unikernels are compiled directly into specialized machine images, you can’t SSH your way into it like in the good old days. Thus, you can’t easily hotfix them in production, preventing configuration drifts.
I think unikernels have a big part to play in the future of immutability in the cloud. So, keep an eye on the technology!
That’s all for now, folks. I hope you’ve enjoyed this post. Please don’t hesitate to share your feedback and opinions. Thanks a lot for reading :-)
Adrian
—
Subscribe to my stories here.
Join Medium for $5 — Access all of Medium + support me & others!