


Climbing out of the Chasm
Unleashing the Potential of Chaos Engineering

Unleashing the Potential of Chaos Engineering

Maturity Comes With Experience, Not Age.
Before diving in, I want to set the stage and briefly explain chaos engineering.
At its core, chaos engineering is the process of:
1 — Making a hypothesis about a particular system
2 — Stressing it
3 —Observing how it responds
4 — Making improvements
5 — Repeat
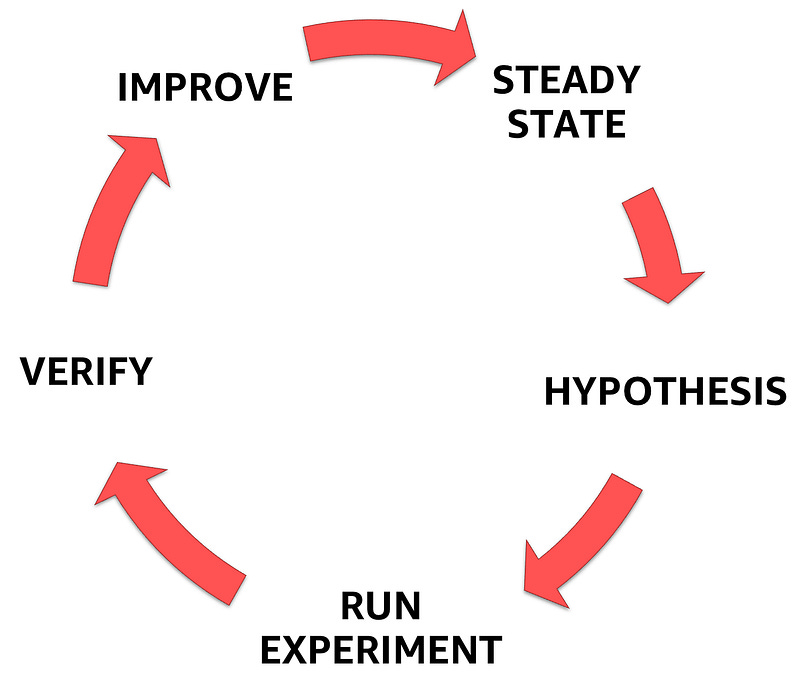
And we do that to prove or disprove our assumptions about our system’s capability to handle these stresses — or disruptive events.
Chaos engineering helps us improve our application’s resilience and performance by uncovering hidden issues and exposing monitoring, observability, and alarm blind spots.
More importantly, chaos engineering gives organizations a platform to practice and excellent operational skills critical to improving recovery time from failures.
Time to recovery is especially critical, and the latest estimations from IDC and the Ponemon Institute are the reasons why.

A hundred thousand dollars — that’s the average cost per hour of infrastructure downtime. Of course, these are averages, but it tells us downtime is potentially very expensive, putting much pressure on businesses.
OK — Now that we are on the same page, I want to tell you a little story.
A little story
A few years ago, I was on a call with a bunch of engineers from a company looking for advice on chaos engineering. What surprised me about this call was how mature these engineers were for their relatively young age. I am not saying that young engineers usually sound immature, but these were pretty different.
Typically, when I consult a company, I listen, ask questions and then talk about my experience and what I have learned. I also often challenge their ideas.
This time, however, they were challenging me and my ideas. I also learned a bunch during that call.
They had only a few years of experience, yet they thought about problems and how to solve them in ways very senior engineers would.
It was a great call, but I was a bit shocked.
They understood in-depth concepts of architecture, distributed systems, and resilience that took me years to understand. But they also displayed powerful soft skills qualities; Intuition, empathy, embracing failure, patience, creativity, kindness, and vulnerability, are some that come to mind first.
It seemed like they had it all and had seen it all.
Since that call, I have had few others like that — with very similar outcomes — me being shocked.
And so recently, I started to wonder what was so special about these calls.
What’s interesting about the qualities displayed by these engineers is that they are not some magical thing that we get overnight.
They typically need a lot of time and exposure to different experiences.
And yet, on the calls with these “seen it all” companies — it seemed that the engineers had hacked their ways into amassing a large amount of experience — but without spending much time doing so.
The negativity bias
Research tells us we naturally —through our negativity bias — learn more from negative outcomes and experiences because we pay more attention to negative events than positive ones. In turn, we make decisions based on negative information more than positive data.
The bad things grab our attention, stick to our memories, and later influence our decisions.
For engineers, outages are really what makes us a lot better and a lot sharper.
And if I look at myself — I can easily say that the most I learned were typically following outages — like when I deleted a database in production. I made plenty of other mistakes, and I can honestly say that it is from these events that I learned most and grew as an engineer.

So how did these companies hack the space-time continuum?
How did they get so much experience in such a short time?
They all had one thing in common — they had fully embraced chaos engineering.
So instead of waiting to learn through painful, unplanned, and customer-impacting events, they controlled the narrative. And in the process, they found a way to hack their way to acquiring the maturity and experience it would have usually taken years to get.
Chaos engineering is an excellent practice to accelerate the learning necessary to build and operate systems, but also to recover them from an outage.
Chaos engineering is a compression algorithm for experience.
A good start, but
In the past few years, Chaos Engineering has been getting much attention.
While 5 or 6 years ago, chaos engineering was still an engineering marvel, something only a few could do; the discipline has picked up in the past couple of years.
My colleague tracked all the public stories about chaos engineering and collected them into this GitHub repository.

Financial services are one of the industries quickly ramping up with chaos engineering.
Itau Brazil, Capital One, JPMC, Vanguard, and Stripe are among the most well-known that talk about it.
In the Media and Entertainment industry, Slack, Prime Video, Audible, and of course, Netflix.
Telcos also jump on the train with Twillio, Orange, and T-Mobile.
So does the Transport & airline industry with Alaska Airlines, Uber, and Lyft.
Hospitality, Gaming, Fashion, ERP, and even the Government — customers in every industry have embraced the practice in some form or another.
It all sounds great.
Unfortunately, that is still a drop in the ocean.
Many companies may have started their chaos engineering journey, but plenty haven’t — and the ones that did start often end up stuck.
Let’s try to understand why.
The five modes of resilience testing
Roughly speaking, we can categorize resilience testing into five different modes:

Ad-hoc testing is an informal or unstructured testing mode to find possible defects or errors. Ad-hoc testing is done randomly, and it is usually an unplanned activity that does not follow any particular techniques to create test cases.
CI/CD pipeline testing is about testing at earlier stages of the release pipeline and testing everywhere, that is, across environments, operating systems, and devices.
GameDays are like fire drills, used to prepare and practice a team’s actions if an event happens, from engagement to incident resolution. GameDays regularly let teams build the necessary muscle memory to respond to these events.
Canary testing is a strategy often used in release pipelines to reduce the risk of introducing issues in production and is typically referred to as a canary release pipeline. It is used to get an idea of how an application will perform in production by (gradually) routing a small percentage of users to a different version (canary). Canary testing is also often used for phased or incremental rollout.
Finally, Continuous testing is a test of ultimate confidence in the system to withstand turbulent conditions since it aims at testing in the environment itself (in production).
What does this have to do with Chaos Engineering?
Ideally, we want our chaos engineering journey to progress across these five different modes because that’s when we get all the benefits.
Today, most chaos engineering practices are stuck in the Ad-hoc or GameDay mode. We slowly start to talk about chaos “testing” earlier in the development process — what’s called “shifting left” — but even that is just the beginning.
There is still a long road ahead to unleash the full potential of chaos engineering.
The Chasm
In the book Crossing the Chasm, Geoffrey A. Moore introduces the Technology Adoption Life Cycle — which begins with innovators and moves to early adopters, early majority, late majority, and laggards.
He explains that the fun of technology often drives innovators and early adopters and that they will happily make sacrifices just to be first. However, the early majority typically waits until they know the technology improves productivity.

It is essential to realize that there is a chasm between the early adopters and the early majority. It means that once innovators and early adopters have adopted our product, we have to adapt to the target market; we might have to change the whole product concept and the product’s positioning, build a different marketing strategy, choose a different distribution channel, and also change the pricing.
Doing these changes is what the author calls “Crossing the Chasm.”
Interestingly, the “Crossing the Chasm” theory is not just for the common adoption of technology within the general population; it also applies to the diffusion of technology within a company.
And it explains why some teams adopt new concepts and ideas before all others and why different teams within a company can be so different.
And it is also one of the reasons why many companies are stuck in the “Chaos Engineering Chasm.”
Chaos Engineering Chasm
The chaos engineering Chasm happens when some teams within an organization are interested, and some might even successfully start their chaos engineering journey. Still, they find it hard to get the discipline stick as a standard practice within their organization.
That’s because that team might be part of the innovators or early adopters.
In other words, that team has what we call “chaos champions.” For the love of technology, these champions are more than willing to put up with the sharp edges.
But the rest of the organization doesn’t follow — They need to be convinced of the improvements in productivity before anything else, and they don’t buy it blindly.
So, how do we climb out of that chasm?
How do we spread our love for chaos engineering to the rest of our organization?
How do we help them get started?
How do we convince them that what we do is vital for the business?
In the rest of this blog post, I will discuss five ideas that I hope can help you climb out of the chasm:
1 — Understanding the Why
2 — Setting goals
3 — Getting started
4 — Reinforcing Mechanisms
5 — Anything is better than nothing
1 — The Why
In the book — Start with Why: How Great Leaders Inspire Everyone to Take Action — Simon Sinek explains what it means to start with Why and how it can create true, lasting success for us and our businesses.
He argues that decisions that start with the Why win hearts and minds.
In his book, Simon presents a Golden Circle with three levels of decision-making.
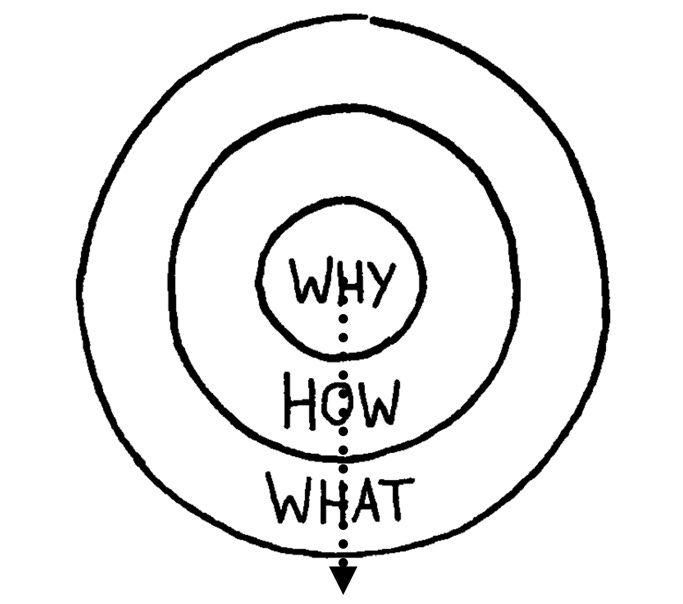
Why — This is the core belief of the business, and it’s why it exists.
How — This is how the business fulfills that core belief.
What — This is what the company does to fulfill that core belief.
Simon explains that the Why helps us understand why we do what we do and that we can achieve more if we remind ourselves to start everything we do by first asking why.
Starting with the Why is equally essential with chaos engineering. When we try to convince others to start with chaos engineering, we usually start with the what and how but rarely explain the Why.
That’s because most of us are engineers in the innovator and early adopter group, and we think everyone else is like us, interested in the what — the technology itself. We believe it is cool and forget why we use it in the first place.
And that’s wrong.
To convince others to get started — we have to explain the Why. We have to convince them of the improvement chaos engineering brings to the business before anything else.
And breaking things isn’t why we do chaos engineering.
Oh, it is fantastic to break things up — I am guilty of it myself — but that’s not how we will convince others to embark on the journey, especially not the CEOs or CTOs.
“Wait, you want to break things? Yeaaaa, no.” — Any Ceo
It might sound silly like that, but making it crystal clear Why we need chaos engineering helps us rally people behind the discipline and make us more engaged with it in the process.
It also will help business leaders buy into what we are trying to achieve.
And as I hinted at the beginning of that talk, linking chaos engineering to the cost of downtime and how it can help reduce it speaks to business, and that is money.
Finally, understanding the Why will help with one of the most critical aspects of chaos engineering — Goals.
2 — Setting Goals
Research has found that goal setting increases employee motivation and organizational commitment and also affects the intensity of our actions. The more complex a goal is, the more intense our efforts will be to attain it and the more success we experience.
In the past seven years, I have talked with customers about chaos engineering; setting goals is probably the most underrated needle mover. Not setting goals for our chaos engineering practice is the number one factor for getting stuck.
How can we convince our organization to stay invested in chaos engineering — a relatively expensive discipline — if we don’t have goals?
What sort of goals are we talking about?
We can have many different goals — some focused on user experience, some focused on service recovery, some on adoption, some on the experiment, and even some on metrics.
We can have team, organization, or company-wide goals.

All of them are valid —we simply need to find what works for us and ensure it aligns with the Why.
However, regardless of the goals, the most successful companies I have seen when it comes to chaos engineering have always had top-down goals.
Goals taken by leadership are the best way to drive long-term chaos engineering. Especially when these leadership goals are tracked through monthly or quarterly business reviews, and it helps keep the momentum.
To find our goals, look inside our organization.
Is there an event or a capability that we need to prepare for? Is there a senior leadership goal that we can leverage?
It doesn’t have to be a great goal, but it can also be very tactical.
Let me give some examples of a few different goals taken by the team at Amazon and AWS related to chaos engineering.
Resilient Architecture Goal
In March 2020, Prime Video launched Prime Video profiles, which give users recommendations, season progress, and a watchlist — new services built on Amazon EC2.
These services are part of a distributed system, and they call other internal Amazon services over the network.
Testing this service’s timeouts, retries, and circuit-breaker configurations was considered critical. Confirming that API timeouts do not exceed a particular limit became one of the goals.
And so Prime Video went on to build ChaosRunner, an open-source framework for injecting fault in service dependencies while generating load against that service. In the process, they leveraged some of my scrappy SSM documents for injecting faults into EC2 instances.
As a result, timeouts, retries, and circuit-breaker configurations were validated by running chaos experiments, and they discovered a bug in the cache of that new service. That bug fix prevented a customer-impacting failure from happening.

Today, Prime Video continues to take all sorts of goals. Many relate to upcoming live events such as English Premier League (EPL) or the National Football League (NFL).
In her talk “Improving Business Resiliency” Olga Hall explains how goals have helped Prime Video push forward its chaos engineering journey.
Service Recovery Goals.
The AWS Lambda team took a goal for their 80+ services to be able to evacuate from an Availability Zone failure within five minutes and weight-back after impacts cease. With that goal in mind, the Lambda team developed automation that shifts customer traffic away from any affected Availability Zone to healthy ones, a process called Availability Zone evacuation. Lambda built a tool that detects failures, performs the Availability Zone evacuation when needed, and uses AWS Fault Injection Simulator (AWS FIS) to inject a series of faults and verify their evacuation strategy worked as expected. This goal eventually led automation to cut the time to the first action from 30 minutes to less than 3 minutes.

User-Experience Goal
Amazon Search extensively uses chaos engineering, and its primary goal is to be ready for Prime Day any day. Amazon Search is what powers the search bar on the main amazon.com page.

We’re talking about millions of products and about 300 million active users. To give a sense of scale, during the last Prime Day, the traffic on the search bar was approximately 84,000 requests per second. Search is such a critical part of the shopping experience that the Search team has its own resilience team, responsible for the resilience of the 40 services that power the search bar.
What is interesting about the Search team is that they have taken an interesting approach to chaos engineering, and we could call it customer-obsessed chaos engineering.
As you probably already know, chaos engineering is about validating a hypothesis. For the Search team, that hypothesis is framed within a Service Level Objective (SLO) and an error budget — a sort of contract that establishes customer experience. Here is an example SLO. It is not one they use, but it will give you a sense of the idea:
In a 28-day trailing window, we’ll see 99.9% of requests with a latency of less than one second.
That’s the SLO.
From that SLO, they can derive the error budget.
99.9% of requests with a latency of less than one second means that .1% can be greater than a second.
That is the budget.
Every request that exceeds one second consumes that budget, and eventually, it is consumed, and they run out of budget.
How fast that budget is burned is called the burn rate. A fast burn rate warns of a sudden, significant change in consumption that can exhaust the error budget quickly.
Now, remember there is a 28-day trailing window. So the oldest requests greater than a second will eventually age out after 28 days. That SLA and error budget is a customer-focused way to drive chaos engineering. And it works for the Search organization.
To learn more about how Amazon Search does chaos engineering, check out this talk from reInvent 2020 — How Amazon Scales in the Cloud.
Metric-Oriented Goal
It is a more controversial one. But I have seen it work well, so I want to share that with you too.
That is — Using a Resilience Score to drive chaos engineering.
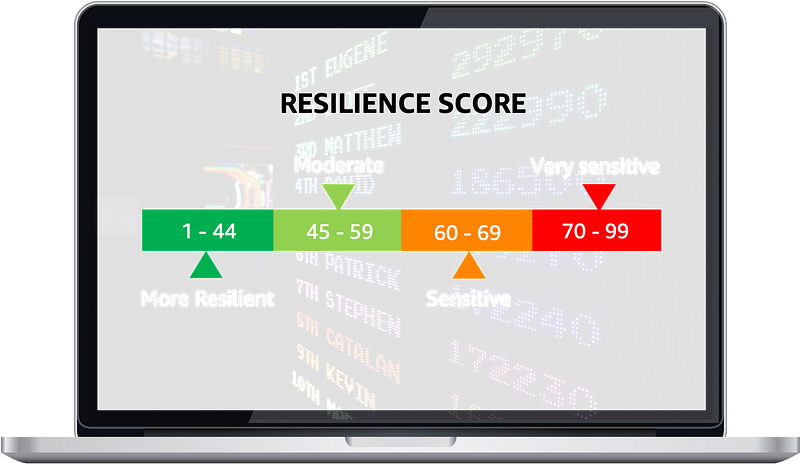
Typically, a resilience score is calculated by awarding points to services that adopt proven resilience best practices to mitigate known availability risks. The score can reflect how closely the application follows recommendations for meeting the application’s resiliency policy, alarms, standard operating procedures, tests, and chaos engineering experiments. That score can allow service owners to track their efforts to become more resilient objectively. A low score indicates something that needs attention and points the team to it. A resilience score is more about teaching risks than aggregating data across tools.
Summarizing the overall risk posture as a score can be helpful as long as we understand the risks associated with metrics.
Having a resilience score is counter-productive if we don’t show what goes into it —we create a situation where a team with a high “score” has a false sense of positivity.
Metrics can easily be hijacked— for example, when people replace the general idea of the goal or mission with the hard metrics when it is all about the metric.

This is called surrogation. That happens a lot when companies attach a financial incentive to a metric- it is usually a mistake as it only makes people focus on that metric and nothing else.
So if you ever want to use a resilience score as a goal, don’t attach a financial incentive to it, and make sure there are other metrics that define the team’s success. Instead, mix it with multiple other metrics or goals.
3 — Getting started
If you have been trying to spread the love for chaos engineering to the rest of your organization — you have probably heard that one.
“How can we start?” — ”What hypothesis should we start with?”
It is by far the most common question I get.
And while I used to try to take a deeper look into the system and how it is built, I now typically ask a couple of questions.
And the first one I ask developers and operation teams is:
What are you worrying about?
That is a compelling question — because often, if your team worries, it is intuition-based and serious.
So severe that this question — ”What are you worrying about?” — is part of the Operational Readiness Review (ORR) we do at Amazon before launching a new service.
If several team members worry about the same thing, rank it up. And then design experiments that address these concerns.
Listening to intuition is always a good use of time.
Quit the opposite — BUT — there is always a BUT.
Have you heard the saying?
Dogs Not Barking
The reference is to Sir Arthur Conan Doyle’s Sherlock Holmes story, The Adventure Of Silver Blaze. At one point, inspector Gregory asks Holmes:
Gregory: Is there any point to which you would wish to draw my attention?
Holmes: To the curious incident of the dog in the night-time.
Gregory: The dog did nothing in the night-time.
Holmes: That was the curious incident
The lesson of ‘dogs not barking’ is to pay attention to what isn’t there, not just what is.
Absence is just as important and just as telling as presence.
Paying attention to absence requires intentional focus.
So the second question I ask is:
What are you NOT worrying about?
With that question, I tackle biases and over-confidence, such as.
“This system never failed; no need to test it.”
And often, it turns out the systems did fail, but no one realized because there were no monitors or alarms in place — Dog not barking.
Defining the service criticality and degradation pattern
Another way to get started is by first looking at the anatomy of an outage. It looks something like that:

It starts with Detection, then Evaluation, Response, Recovery, and eventually Confirmation.
If you remember my early comment about the cost of outages, it is easy to understand why improving the timing for each phase is critical.
John Allspaw, Founder and Principal at Adaptive Capacity Lab, said:
“Being able to recover quickly from failure is more important than having failure less often.”
I couldn’t agree more with that. And I would add — to recover quickly, you need to practice — a lot.
Recovering is not a binary solution since distributed systems are often built out of hundreds of dependencies or services, and some are more critical than others.
Imagine our company’s business provides email service to our customers; the critical functions are to receive and send emails. The rest is good-to-have, normal operations: e.g., filters, calendar integration, address book, etc.

Every service has some criticality levels — and during an outage, understanding these levels helps us prioritize what we should do.
Take a moment to think about your application.
Do you have a clear understanding of the service criticality?
At a minimum, we need to define our “normal operations” and” minimal critical operations” modes.
We can, of course, have more levels of criticality — but this is the bare minimum.
Then we can work out the different recovery plans for each mode- from short to long-term — and verify them with chaos engineering experiments.
That is chaos engineering focused on reducing time to recovery — and this is where the money is.
4 — Reinforcing mechanism
Getting started is excellent — but how can we keep the momentum?
The answer is mechanism — or processes. Let me share two I think to make a big difference.
Operational Readiness Review (ORR)
ORR is a rigorous mechanism for regularly evaluating workloads, identifying high-risk issues, and recording improvements. It is an evidence-based assessment that evaluates a service’s operational state and is often very specific to a specific company, its culture, and its tools.
ORR all have the same goal: help us find blind spots in our operations.
In a nutshell, ORR is done by reviewing a list of questions that a team launching a service or critical feature must answer.
Typically, ORR is led by Senior or Principal Engineers — and if we don’t sign them off, the particular service or feature won’t launch.
One of the questions in the ORR is, “What is your GameDay plan?”
For that question, teams must enumerate dependencies and component failure scenarios and develop a comprehensive plan to verify that they fail and recover as expected.
That’s a good way to enforce chaos engineering if you ask me.
Now — this is very peculiar to Amazon to have senior engineers able to pull the plug on a launch. Not every company I worked with would have accepted that. Again, it is a very cultural thing. But it works.
Notice that the question gives a lot of room for interpretation, though, so it is also up to us to have good judgment and know when to pull the plug.
Wins
Sharing wins is another excellent way to move forward with chaos engineering, especially once we start.
When a team does something cool or breaks its goal — celebrate it. Write emails to company-wide mailing lists. Write blog posts.
While doing all these things, we also discuss them during our AWS-wide weekly ops meeting. That meeting has a lot of visibility across the company, with our most senior leaders often leading the show.
When we share a win, we also share the details of how we got there. And that is a great way to promote learning by sharing best practices across the organization.
Celebrating chaos engineering wins is a great way to tell the teams on the ground that leaders care about it.
5 — Anything is better than nothing
“Sometimes, the journey teaches you a lot about your destination.” — Unknown
Humans are sometimes obsessed with comparison and validation, which often makes us rely on others’ approval for self-validation and goals, leading to self-doubt. While this is especially true for social media, it is equally valid for technology.
What we read in the blogs or hear at conferences is only one side of the story — and it is often the successes, not the struggles.
The truth is that everyone struggles when it comes to chaos engineering. Injecting faults in a system is one of the most daunting things for an engineering team.
Reading about how X or Y is doing chaos engineering — in production — can make us feel inadequate.
But trust me, even the companies you believe are supposedly great at chaos engineering struggle. Not all teams, squads, and organizations are equal, and some workloads are more chaos-friendly than others.
You are not as far behind as you may think.
A very old French slogan of the Loto company says:
« 100% des gagnants ont tenté leur chance ».
Which translates to:
« 100% of the winners tried ».

Trying our luck with chaos engineering is more important than succeeding because the people, teams, and organizations who get started are the only ones who can finish anything.
Starting Now means we don’t have to wait for everything to be perfect.
Hacking our way to it and doing things manually if necessary is OK!
We don’t need to be experts to learn the most basic lessons in chaos engineering.
When Amazon started in 2001 — Jesse Robbins, known as the Master of Disaster — started by unplugging servers in data centers. Over time, with tears and sweat, the program evolved and has become more sophisticated. But the first step was over 20 years ago! And we are still learning today.
When I started with chaos engineering, no public tools were available, and we had no choice but to axe our way down the stack.
Today, more tools are available directly built by cloud providers and by 3rd parties. All are still improving, but they will help you get started.
Yes, we still need to get our sleeves up, but who doesn’t like a bit of oil on the hands?
It’s also like that for the rest of Life.
What if the choice to be curious was all required to become more innovative and more skilled?
What if the willingness to try something new, even if it feels uncomfortable, is all it takes to start the slow march toward success?
The truth is we learn more from the process of pursuing excellence than from the products of achieving it.
The more I think about it, the more I believe that the willingness to start in Life makes the most significant difference.
And I can’t think of any skill more critical to the successful pursuit of chaos engineering than the willingness to start.
On culture, tools, and mechanism
Each system is unique, so the lessons we learn on one side of the organization might only apply in some places.
It takes three interconnecting elements to operate the technology we build successfully:
We need to have the right culture.
We need great tools.
We need complete processes.

Chaos Engineering is the technology in focus here.
Each organization develops in its unique way.
What is essential to understand from that interconnectivity between culture, tools, and processes is that we cannot expect to have a successful chaos engineering journey if we only focus on the tools — which is, unfortunately, a common mistake I see.
We must nurture a culture and the processes that support our chaos engineering journey.
If we don’t do that, we will stay stuck in the chasm — unable to move forward.
That’s all, folks. I hope I have given you some ideas for moving forward with your chaos engineering journey. Don’t hesitate to give me feedback, share your opinion, or clap your hands. Thank you!
Adrian
—
Subscribe to my stories here.
Join Medium for $5 — Access all of Medium + support me & others!