
Chaos Engineering — Part 3
Failure Injection — Tools and Methods

Failure Injection — Tools and Methods.

I would like to express my sincere gratitude and appreciation to my good friend Ricardo Sueiras for his review, input and for un-stucking me from this blog post. Ricardo, you are a legend!

It’s important to remember that chaos engineering is NOT about letting monkeys loose and injecting failure randomly without a purpose. Chaos engineering is a well-defined, formalized scientific method of experimentation.
“It involves careful observation, applying rigorous skepticism about what is observed, given that cognitive assumptions can distort how one interprets the observation. It involves formulating hypotheses, via induction, based on such observations; experimental and measurement-based testing of deductions drawn from the hypotheses; and refinement (or elimination) of the hypotheses based on the experimental findings.” — Wikipedia
Chaos engineering starts with understanding the steady state of the system you are dealing with, followed by articulating a hypothesis, and finally, verifying and learning from experiments to improve the resiliency of the system.
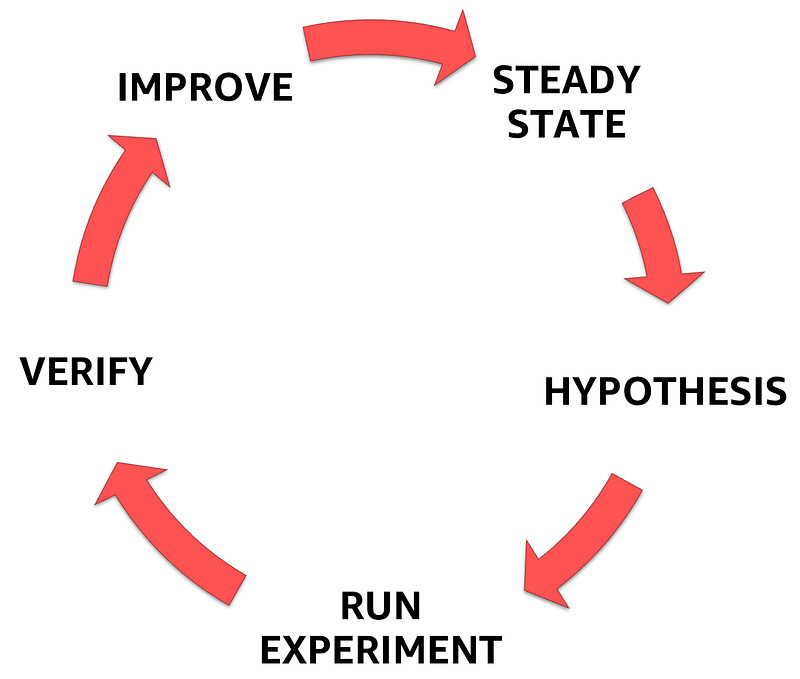
In Part 1 of this blog series, I introduced chaos engineering and discussed each step of the chaos engineering process shown above.
In Part 2, I discussed areas to invest in to start designing your chaos engineering experiments and pick up the right hypothesis.
In this Part 3, I focus on the experiment itself and present a collection of tools and methods that cover the broad spectrum of failure injection necessary for running chaos engineering experiments.
This list isn’t exhaustive, but it should be enough to get you started and give you food for thought.
Failure injection — what is it, and why do we do it?
Failure injection aims to understand and verify if the response of a system conforms with its specifications under normal stress conditions. It’s a technique that was first used to induce faults at the hardware level — specifically, at pin-level — by changing the electrical signals on hardware devices.
In software engineering, failure injection helps improve the resiliency of a software system and enables the correction of potential failure tolerance deficiencies in that system. This is called fault removal. It also helps evaluate the potential impact of failure — i.e., its blast radius — before it occurs in production. This is called failure forecasting.
Failure injection has several key benefits:
Understand and practice contingency and incident response.
Understand the effects of real-world failures.
Understand the effectiveness and limits of fault tolerance mechanisms.
Remove design faults and identify single points of failure.
Understand and improve the observability of the system.
Understand the blast-radius of failures and help reduce it.
Understand failure propagation between system components.
Categories of failure injection
Failure injections are classified into 5 categories: failure injection at the (1) resource level; (2) network and dependencies level; (3) application, process, and service level; (4) infrastructure level; and (5) people level**.
I will now examine each category and provide an example of failure injection for each. I will also look at all-in-one failure injection and orchestration tools.
**Note: I won’t cover failure injection at people level in this blog, but will cover the topic in a future post.
1 — Resource level failure injection — a.k.a resource exhaustion.
Even though the cloud has taught us resources are almost infinite, I’m sorry to disappoint you — they aren’t. An instance, a container, a function, etc. — regardless of the abstraction, resources will eventually be constrained. Pushing the limits in that danger-zone, where resources are scare, is called resource exhaustion.

Resource exhaustion tends to simulate a denial-of-service attack, only not the commonly distributed ones, to interfere with the targeted host. They are common failure injections, probably because they are easy to do.
Exhausting CPU, memory, and I/O.
One of my favorite tools is stress-ng, a re-write of the original stress tool by Amos Waterland.
With stress-ng, you can inject failure by stressing various physical subsystems of a computer as well as the operating system kernel interfaces, using stressors. The following stressors are available: CPU, CPU-cache, device, IO, interrupt, filesystem, memory, network, OS, pipe, scheduler, and VM. The man pages include a full description of all the stress tests available — 220 of them!
Following are a few useful examples of how to use stress-ng:
The matrixprod CPU stress provides the right mix of memory, cache, and floating-point operations and is probably the best method to make a CPU run hot.
❯ stress-ng —-cpu 0 --cpu-method matrixprod -t 60siomix-bytes stress writes N bytes for each iomix worker process; the default is 1 GB and, it is ideal for performing IO stress tests. In this example, I specify 80 % of the free space on the file system.
❯ stress-ng --iomix 1 --iomix-bytes 80% -t 60s vm-bytes is excellent for performing memory stress tests. In this example, stress-ng runs nine virtual memory stressors that combined use 90% of the available memory for one hour. Thus, each stressor uses 10% of the available memory.
❯ stress-ng --vm 9 --vm-bytes 90% -t 60sExhausting the disk space on hard drives
dd is a command-line utility built to convert and copy files. However, dd can read and/or write from special device files such as /dev/zero and /dev/random for tasks such as backing up the boot sector of a hard drive and obtaining a fixed amount of random data. Thus, it can also be used to inject failures into your host and simulate a disk filling up. Remember when your log-files filled up the server and took your application down? Well, dd can help you — but also hurt you!
Use dd very carefully . Entering the wrong command can wipe, destroy, or overwrite the data on your hard drive!
❯ dd if=/dev/urandom of=/burn bs=1M count=65536 iflag=fullblock &Exhausting application APIs
The performance, resiliency, and scalability of APIs matter. Indeed, APIs are now essential for companies to build applications and grow their businesses.
Load testing is a great technique to test an application before it reaches production. It is also an excellent stress method as it will often surface exceptions and limits that otherwise would not surface until faced with real-life traffic.
wrk is an HTTP benchmarking tool that can generate significant load on systems. I especially like hammering health-check APIs — more so if there are deep health checks, because they reveal a great deal about the design decisions made upstream: How is cache setup? How is rate-limiting implemented? Does the system prioritize health-checks from the load balancers?
Here is a good starting point:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/healthThis command runs twelve threads and keeps four hundred HTTP connections open for twenty seconds.
2 — Network and dependencies level failure injection
The Eight Fallacies of Distributed Computing by Peter Deutsch are a set of assumptions that developers make while designing distributed systems. However, they often backfire, triggering outages and prompting system redesigns. The assumptions are:
The network is reliable.
The latency is zero.
Bandwidth is infinite.
The network is secure.
Topology doesn’t change.
There is one administrator.
Transport cost is zero.
The network is homogeneous.
This list is a useful starting point for selecting failure injections and testing the resiliency of your distributed system to withstand network failures.
Injecting latency, loss and corrupting the network
tc (traffic control) is a Linux command-line tool used to configure the Linux kernel packet scheduler, which defines how packets are queued for transmission and reception on a network interface. The operations include enqueuing, policing, classifying, scheduling, shaping, and dropping.
You can use tc to simulate packet delay and loss for UDP or TCP applications or limit the bandwidth usage of a particular service to simulate Internet traffic conditions.
—Injecting 100ms of delay
#Start
❯ tc qdisc add dev etho root netem delay 100ms#Stop
❯ tc qdisc del dev etho root netem delay 100ms— Injecting 100ms of delay with a delta of 50ms
#Start
❯ tc qdisc add dev eth0 root netem delay 100ms 50ms#Stop
❯ tc qdisc del dev eth0 root netem delay 100ms 50ms— Corrupting 5% of the network packets
#Start
❯ tc qdisc add dev eth0 root netem corrupt 5%#Stop
❯ tc qdisc del dev eth0 root netem corrupt 5%— Dropping 7% of packets with 25% correlation
#Start
❯ tc qdisc add dev eth0 root netem loss 7% 25%#Stop
❯ tc qdisc del dev eth0 root netem loss 7% 25%Note: 7% is enough that TCP will not fail.
Messing with “/etc/hosts” — a static table lookup for hostnames
/etc/hosts is a simple text file that associates IP addresses with hostnames, one line per IP address. For each host a single line should be present with the following information: IP_address canonical_hostname [aliases...]

This hosts file is one of several systems that addresses network nodes in a computer network and translates human-friendly hostnames into IP addresses. And, you guessed right, it makes it pretty convenient to trick computers, too. Here are few examples:
Blocking access to DynamoDB API from an EC2 instance
#Start
# make copy of /etc/hosts to /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 dynamodb.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 dynamodb.eu-north-1.amazonaws.com" >> /etc/hosts#Stop
# copy back the old version /etc/hosts
❯ cp /etc/hosts.back /etc/hostsBlocking access to EC2 API from an EC2 instance
#Start
# make copy of /etc/hosts to /etc/host.back
❯ cp /etc/hosts /etc/hosts.back
❯ echo "127.0.0.1 ec2.us-east-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-east-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.us-west-2.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-west-1.amazonaws.com" >> /etc/hosts
❯ echo "127.0.0.1 ec2.eu-north-1.amazonaws.com" >> /etc/hosts#Stop
# copy back the old version /etc/hosts
❯ cp /etc/hosts.back /etc/hostsSee it in action below — Initially, the EC2 API is accessible and ec2 describe-instances returns successfully.

Once I add 127.0.0.1 ec2.eu-west-1.amazonaws.com to /etc/hosts, the EC2 API call fails.

Of course, this works for all AWS endpoints.
I could tell you a joke about DNS…

… But it will take 24 hours for you to get it.
On October 21, 2016, the Dyn DDoS attack caused a significant number of Internet platforms and services to be unavailable in Europe and North America. According to the 2018 ThousandEyes Global DNS Performance Report, 60% of enterprises and SaaS providers still rely on a single source of DNS provider and thus are not resilient to DNS failures. Since without DNS, the internet is no more, it is an excellent idea to simulate a DNS failure to evaluate your resiliency to the next DNS outage.
Blackholing is a method traditionally used to mitigate a DDoS attack in which bad network traffic is routed into a “black hole” and thrown into the void. The networking version of /dev/null:-). We can use this to simulate the loss of network traffic or protocol, for example, the loss of DNS.
The right tool for the job is iptables, which is used to set up, maintain, and inspect the tables of IP packet filter rules in the Linux kernel.
To blackhole DNS traffic, try the following:
#Start
❯ iptables -A INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -A INPUT -p udp -m udp --dport 53 -j DROP#Stop
❯ iptables -D INPUT -p tcp -m tcp --dport 53 -j DROP
❯ iptables -D INPUT -p udp -m udp --dport 53 -j DROPFailure injection using Toxiproxy.
One of the significant issues with Linux tools such as tc and iptables is that they require root permission to execute, which can be problematic for some organizations and environments. Please welcome Toxiproxy!
Toxiproxy is an open-source TCP proxy developed by the Shopify engineering team. It helps simulate the chaotic network and system conditions of real-life systems. You put Toxiproxy in between different components of your architecture, as bellow.

It’s made specifically for testing, CI, and development environments, and supports deterministic or randomized chaos as well as customization. Toxiproxy uses toxics to manipulate the connection between the client and upstream and can be configured via an HTTP API. And, it comes with enough default toxics to get started.
The below example shows Toxiproxy running with a downstream toxic injecting 1000ms of latency in the connection between my Redis client, redis-cli, and Redis itself.
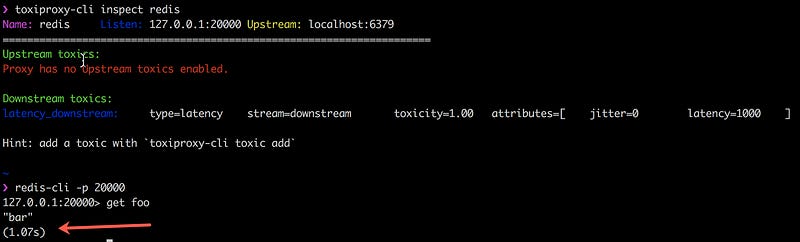
Toxiproxy has been successfully used in all development and test environments at Shopify since October 2014. See their blog post for more information.
3 — Application, process and service level failure injection
Software crashes. It is a fact. What do you do when it fails? Should you log in via SSH in your server and restart the failed process? Process control systems provide state or change of state control functions such as start, stop, restart. Control systems are typically implemented to provide stable control of the process. systemd is such a tool, providing the fundamental building blocks to manage processes for Linux. Supervisord offers controls to several processes on UNIX-like operating systems.
When you deploy your application, you should make use of these tools. It is, of course, good practice to test the impact of killing critical processes. Make sure you get notified and that processes restart automatically.
— Killing Java processes
❯ pkill -KILL -f java#Alternative
❯ pkill -f 'java -jar'— Killing Python processes
❯ pkill -KILL -f pythonOf course, you can use the pkill command to kill pretty much any process running in the system.
Database failure injection
If there are failures people on-call don’t like to receive, it’s ones related to database failures. Data is gold, and thus every time a database fails, the risk of losing customer data increases.

The ability to recover the data and get the system back up-and-running as quickly as possible can even sometimes decide the future of the company. Unfortunately, it is also not always easy to prepare for different database failure modes — and many will end-up surfacing in production.
However, if you use Amazon Aurora, you can test the fault tolerance of your Amazon Aurora DB cluster by using fault injection queries.
Amazon Aurora fault injection
Fault injection queries are issued as SQL commands to an Amazon Aurora instance, and they enable you to schedule a simulated occurrence of one of the following events:
A crash of a writer or reader DB instance.
A failure of an Aurora Replica.
A disk failure.
Disk congestion.
When you submit a fault injection query, you also specify an amount of time for the failure event simulation to occur.
— Force a crash of an Amazon Aurora instance:
ALTER SYSTEM CRASH [ INSTANCE | DISPATCHER | NODE ];— Simulate the failure of an Aurora Replica:
ALTER SYSTEM SIMULATE percentage PERCENT READ REPLICA FAILURE
[ TO ALL | TO "replica name" ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— Simulate a disk failure for an Aurora DB cluster:
ALTER SYSTEM SIMULATE percentage PERCENT DISK FAILURE
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };— Simulate a disk failure for an Aurora DB cluster:
ALTER SYSTEM SIMULATE percentage PERCENT DISK CONGESTION
BETWEEN minimum AND maximum MILLISECONDS
[ IN DISK index | NODE index ]
FOR INTERVAL quantity { YEAR | QUARTER | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND };Failures in the serverless world
Injecting failure can be challenging if you are using serverless components, since serverless managed services such as AWS Lambda don’t natively support failure injection.
Injecting failures into Lambda functions
To address this issue, I wrote a small python library and a lambda layer for injecting failures into AWS Lambda. Both currently support latency, errors, exceptions, and HTTP error code injection. Injecting failure is achieved by setting AWS SSM Parameter Store as follows:
{
"isEnabled": true,
"delay": 400,
"error_code": 404,
"exception_msg": "I really failed seriously",
"rate": 1
}You can add a python decorator to the handler function to inject failure.
—Raise exception:
@inject_exception
def handler_with_exception(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_exception('foo', 'bar')
Injecting exception_type <class "Exception"> with message I really failed seriously a rate of 1
corrupting now
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../chaos_lambda.py", line 316, in wrapper
raise _exception_type(_exception_msg)
Exception: I really failed seriously— Inject wrong HTTP error code:
@inject_statuscode
def handler_with_statuscode(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}
>>> handler_with_statuscode('foo', 'bar')
Injecting Error 404 at a rate of 1
corrupting now
{'statusCode': 404, 'body': 'Hello from Lambda!'}— Inject delay:
@inject_delay
def handler_with_delay(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}>>> handler_with_delay('foo', 'bar')
Injecting 400 of delay with a rate of 1
Added 402.20ms to handler_with_delay
{'statusCode': 200, 'body': 'Hello from Lambda!'}To learn more about this python library, click here.
Inject failure to Lambda execution via concurrency limit
Lambda uses a default safety throttle for concurrent executions across all functions in a given region, per account. Concurrent executions refer to the number of executions of function code occurring at any given time. It is used to scale the function’s invocation to incoming requests. It can, however, serve for the inverse purpose: stalling Lambda execution.
❯ aws lambda put-function-concurrency --function-name <value> --reserved-concurrent-executions 0This command will force concurrency to zero, causing requests to fail with a throttling error — 429 status code.
Thundra — Tracing serverless transactions
Thundra, a tool used for serverless observability, has a built-in capability to inject failure in serverless applications. This uses span listeners to inject failures such as a missing error handler for DynamoDB operations, a missing fallback for a data source, or a missing timeout on outbound HTTP requests. I haven’t tried it myself, but this blog post written by Yan Cui and this great video from Marcia Villalba describe the process well — and it looks promising.
To close that serverless section, Yan Chui wrote an excellent article about the challenges of chaos engineering for serverless applications which I recommend everyone read.
4 —Infrastructure level failure injection
Infrastructure level failure injections are where it all started — both for Amazon and Netflix. From disconnecting an entire data-center to randomly stopping instances, infrastructure level failure injection is probably the simplest to undertake.
And naturally, the first that comes to mind is the chaos monkey example.
Randomly stopping an EC2 instance in an availability zone.
In its early days, Netflix wanted to enforce robust architectural guidelines. It deployed its chaos monkey as one of the first applications on AWS to enforce stateless auto-scaled micro-services — meaning that any instance can be terminated and replaced automatically without causing any loss of state. Chaos monkey made sure no one broke this guideline.
The following script — similar to chaos monkey — randomly stops any instance, in a particular AZ within a region.
❯ stop_random_instance(az="eu-west-1a", tag_name="chaos", tag_value="chaos-ready", region="eu-west-1")Notice the filter based tag_name and tag_value? Small things like that will prevent the wrong instance from shutting down. #lessonlearned

5— All-in-one failure injection and orchestration tools
There is a good chance that you might be overwhelmed by all the different tools presented thusfar. Fortunately, there are a couple of failure injection and orchestration tools out there that package most of the above in an easy to use way.
Chaos Toolkit
One of my favorite tools out there is Chaos Toolkit, an open-source platform for chaos engineering, which is supported commercially by the excellent ChaosIQ team — Russ Miles, Sylvain Hellegouarch, and Marc Perrien, to name a few.
Chaos Toolkit defines a declarative and extensible open API to express your chaos engineering experiment. It includes drivers for AWS, Google Cloud Engine, Microsoft Azure, Cloud Foundry, Humio, Prometheus, and Gremlin.
Extensions are a collection of probes and actions that you use for your experiment as follows — e.g., randomly stop instances in a particular availability zone if tag-key value is chaos-ready.
Running the above experiment is simple:
❯ chaos run experiment_aws_random_instance.json
The strength of Chaos Toolkit is first that it’s open-source and thus extensible to your needs. Second, it fits nicely into a CI/CD pipeline and supports continuous chaos testing.
The downside of Chaos Toolkit is that it’s a learning curve to get started and understand how it lines up. Moreover, it doesn’t come with ready-made experiments, so you will have to write your own. However, I know the team at ChaosIQ is working hard to address this issue.
Gremlin
Another favorite — Gremlin — packages a comprehensive set of failure injection modes in an easy to use tool with an intuitive UI — a sort of Chaos-as-a-Service.
Gremlin supports, resource, state, network, and request failure injections and lets you quickly experiment across your system, including bare metal, different cloud providers, containerized environments including Kubernetes, applications, and — to some extent — serverless.
A bonus — The folks at Gremlin are pretty awesome, create excellent content on their blog, and are always ready to help out! Matthew, Kolton, Tammy, Rich, Ana, and HML, to name a few.
Using Gremlin is straightforward:
First, log in to the Gremlin app and select Create Attack.

Select the target instance.
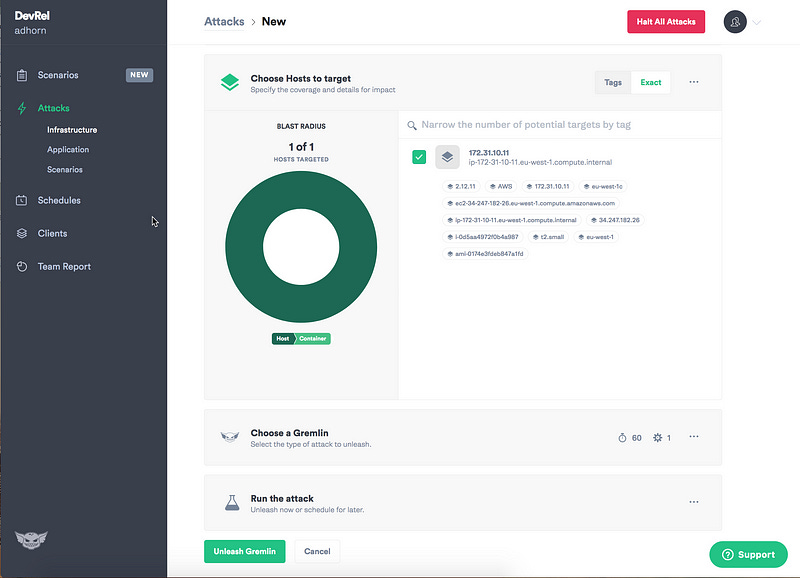
Select the type of failure you want to inject and then unleash!

I have to admit that I’ve always loved Gremlin as it makes chaos engineering experiments intuitive and easy to perform.
The downside for me is the pricing model, which isn’t very beginner or on-demand friendly since it is license based. However, they recently added a free version. Moreover, Gremlin client and daemon need to be installed on the instances it wants to attack, which isn’t to everyone’s liking.
Run Command from AWS System Manager
The EC2 Run Command EC2, introduced in 2015, was built to help administer instances easily and securely. Today, it lets you remotely and securely manage the configuration of your instances — not just EC2 instances, but also the ones configured in your hybrid environment. That includes on-premises servers and virtual machines (VMs) and even VMs in other cloud environments used with Systems Manager.
Run Command allows you to automate DevOps tasks or perform ad-hoc configuration updates, regardless of the size of your fleet.
While Run Command is mostly used for tasks such as installing or bootstrapping applications, capturing log files, or joining instances to a Windows domain, it is also well-suited for performing chaos experiments.
I wrote a blog post dedicated to injecting chaos using AWS System Manager and opened source plenty of ready-made failure injection to get started. Try it — it’s pretty awesome!
Injecting Chaos to Amazon EC2 using AWS System Manager
Ansible, Chef, and Bastion host — these are the standard, widely known tools and techniques, used to execute ad-hoc…medium.com
adhorn/chaos-ssm-documents
Collection of SSM Documents. This allows to conduct small chaos engineering experiments for your Amazon EC2 instances…github.com
Wrap up!
Before finishing this post, I’d like to stress a few essential points regarding failure injections.
1 — Chaos engineering is not about breaking things in production only — it’s a journey. A journey about learning by experimenting in a controlled environment — any environment — whether it’s the local developer environment, beta, staging, or production. That journey can start wherever you are! Olga Hall says it best:
“Meet Chaos where you are. Take it on your own journey.” — Olga Hall, Sr. Manager, Resilience Engineering at Amazon Prime Video
2 — Before injecting failure, remember that it is essential to have an excellent monitoring and alerting program in place. Without them, you won’t be able to understand the impact of your chaos experiments or measure their blast radius — which is critical to sustainable chaos engineering practices.
3 — Some of these failure injections can do real damage, so be careful and ensure your first injections are on test instances where no customers can be affected.
4 — Finally, test, test, and test more. Remember that chaos engineering is all about building confidence in your application — and your tools — to withstand turbulent conditions.
That’s all, folks. Thanks for reading this far. I hope you’ve enjoyed Part 3. Please don’t hesitate to give me feedback, share your opinions, or clap your hands :-)
Adrian
—
Subscribe to my stories here.
Join Medium for $5 — Access all of Medium + support me & others!