

The art of breaking things purposefully


I would like to express my gratitude and appreciation to Adrian Cockcroft for his review, input and for helping me make this blog post better. Adrian’s work on chaos engineering has always been an inspiration for me and today I feel privileged and honored to be able to work with him.
Firefighters— these highly trained specialists risk their lives every day fighting fires. Did you know that before becoming an active-duty firefighter, one needs to spend approximately 600 hours in training? And that’s just the beginning. After that, some firefighters — according to reports — spend over 80% of their active-duty time in training.
Why?
When a firefighter goes under live-fire conditions, she/he needs to have an intuition for the fire they are fighting against. To acquire that lifesaving intuition, she/he needs to train hour after hour, after hour. Like the old adage says, practice makes perfect.

“They seem to get inside the head of the fire, sort of like a Dr. Phil for a fire” — Fighting Wildfires With Computers and Intuition
Once upon a time in Seattle
In the early 2000s, Jesse Robbins, whose official title was Master of Disaster at Amazon, created and led a program called GameDay, a program inspired by his experience training as a firefighter. GameDay was designed to test, train and prepare Amazon systems, software, and people to respond to a disaster.
Just as firefighters train to build an intuition to fight live fires, Jesse’s goal was to help his team build an intuition against live, large-scale catastrophic failures.
GameDay was designed to increase Amazon retail website resiliency by purposely injecting failures into critical systems.
Initially, GameDay started with a series of company-wide announcements that an exercise — sometimes as large as a full-scale data-center destruction — was going to happen. Little detail about the exercise was given and the team had just a few months to prepare for it. The focal point was to make sure regional single points of failure would be tackled and eliminated.
During these exercises, tools and process such as monitoring, alerts and on-calls were used to test and expose flows in the standard incident-response capabilities. GameDay became really good at exposing classic architectural defects but would sometimes also expose what’s called “latent defects” — problems that appear only because of the failure you’ve triggered. For example, incident management systems critical to the recovery process fail due to unknown dependencies triggered by the fault injected.
As the company grew, so did the theoretical blast radius of GameDay, and these exercises were eventually halted as the potential impact on customers of the retail websites grew too large. These exercises have since evolved into different compartmentalized experiments with the intent being to exercise failure modes without causing any customer impact. I won’t touch on these in this blog post, but will do so in the future. In this post, I’ll discuss the bigger idea behind GameDay: resiliency engineering, otherwise known as chaos engineering.
The rise of the monkeys
You’ve probably heard of Netflix — the online video provider. Netflix began moving out of their own datacenter into the AWS Cloud in August 2008 — a push stimulated by a major database corruption that affected shipment of DVDs for three days. Yes, Netflix started by sending movies over the traditional snail mail. The migration to cloud was driven by the need to support a much larger streaming workload and also to move from a monolithic architecture to a micro-services architecture that could scale with both more customers and a bigger engineering team. The customer facing streaming service was moved to AWS between 2010 and 2011, and corporate IT and everything else eventually moved, with the datacenter being closed in 2016. Netflix measures availability as successful customer requests vs. failures to start streaming a movie, not as simple uptime vs. downtime, and targeted and often achieved four nines of availability in each region on a quarterly basis. Their global architecture spans across three AWS regions and they can move customers between regions in the event of a problem in one region.
To repeat one of my favorite quotes:
“Failures are a given, and everything will eventually fail over time.” — Werner Vogels
Indeed, failures in distributed systems, especially at scale, are unavoidable, even in the cloud. However, the AWS cloud and its redundancy primitives — in particular the multi availability zone design principle on which it is built — allows anyone to build highly resilient services.
By embracing the principles of redundancy and graceful degradation, Netflix has been able to survive failures without impacting their customers’ experience.
From the very beginning, Netflix wanted to enforce very strong architectural guidelines. They deployed their Chaos Monkey as one of the first applications on AWS to enforce stateless auto-scaled micro-services — meaning that any instance can be terminated and replaced automatically without causing any loss of state. Chaos Monkey makes sure no-one breaks this guideline.
Netflix has another rule that stipulates that every service should be distributed across three availability zones and keep running if only two of them are available. To prove that this rule remains true, their Chaos Gorilla shuts down availability zones. At a larger scale, Chaos Kong can also evacuate a entire AWS Region to prove that all Netflix customers can be served from any of the three regions. And they run these larger tests every few weeks, in production, to make sure nothing slips by. Finally, Netflix also built more focused Chaos Testing tools to help find problems throughout their micro-services and data storage architecture. Netflix has documented these techniques in their Chaos Engineering book which I highly recommend to anyone interested in the topic.
By running experiments on a regular basis that simulate a Regional outage, we were able to identify any systemic weaknesses early and fix them — Netflix blog
Chaos engineering principles have now been formalized and the following definition given:
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production. http://principlesofchaos.org/
However, in his AWS re:Invent 2018 talk on chaos engineering, the former Netflix cloud architect, Adrian Cockcroft, who helped lead the company’s shift to an all-cloud computing infrastructure, presents an alternative definition of chaos engineering that, in my opinion is a bit more precise and boiled down.
“Chaos Engineering is an experiment to ensure that the impact of failures is mitigated”
Indeed, we know that failures happen all the time, and that they shouldn’t impact customers if they are mitigated correctly — and chaos engineering’s main purpose is to uncover failures that are not being mitigated.
Prerequisites to chaos
Before starting your journey into chaos engineering, make sure you’ve done your homework and have built resiliency into every level of your organization. Building resilient systems isn’t all about software. It starts at the infrastructure layer, progresses to the network and data, influences application design and extends to people and culture. I’ve written extensively about resiliency patterns and failures in the past (here, here, here and here) so I won’t expand on that here, but the following is a little reminder.

The Phases of Chaos Engineering
It’s important to understand that chaos engineering is NOT about letting monkeys loose or allowing them to break things randomly without a purpose. Chaos engineering is about breaking things in a controlled environment, through well-planned experiments in order to build confidence in your application to withstand turbulent conditions.
To do that, you have to follow a well-defined, formalized process described in the picture below, that will take you from understanding the steady state of the system you are dealing with, to articulating a hypothesis, and finally, verifying and learning from experiments in order to improve the resiliency of the system itself.
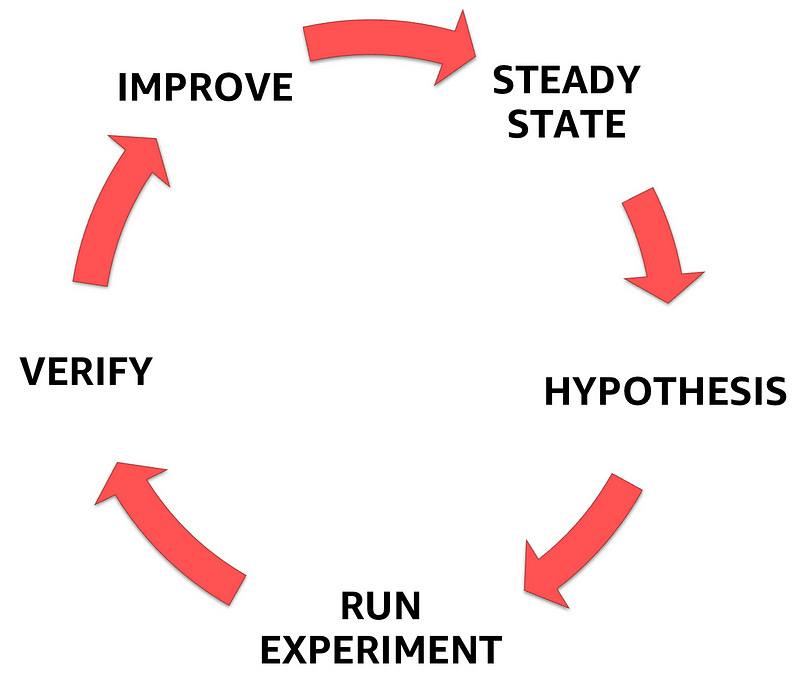
1— Steady State
One of the most important part of chaos engineering is to first understand the behavior of the system in normal conditions.
Why? Simple — after artificially injecting failure, you want to make sure you can return to a well-known steady state and that the experiment is no longer interfering with the system’s normal behavior.
The key here is not to focus on the internal attributes of the system (CPU, memory, etc.) but to instead look for measurable output that ties together operational metrics and customer experience. For that output to be in steady state, the observed behavior of the system should have a predictable pattern but vary significantly when failure in the system is introduced.
Keeping in mind the chaos engineering definition from Adrian Cockcroft defined above, that steady state varies when an unmitigated failure triggers an unexpected problem, and should cause the chaos experiment to be aborted.
To give you some examples of steady state, Amazon retail uses number of orders as one of its steady state metrics — and for good reason. In 2007, Greg Linden, who previously worked at Amazon, stated that through A/B testing, he tried delaying a retail website page loading time in increments of 100ms, and found that even small delays would result in substantial and costly drops in revenue. With every 100ms increase in load time, the number of orders, and thus sales, dropped by one percent. This makes number of orders a great steady state candidate.
Netflix uses a server-side metric related to playback starts — the number of times a user clicks play on the remote control. They realized that the “SPS” (or starts-per-second) had a predictable pattern and fluctuated significantly when failures in the system occurred. The metric is rightly called the Pulse of Netflix.
The number of orders for Amazon and the Pulse of Netflix are really good steady states since they both consolidate customer experience and operational metrics into single, measurable and highly predicable output.
Measure, Measure, and Measure Again.
It goes without saying that if you can’t properly measure your system, you can’t monitor drifts in the steady state or even find one. Invest in measuring everything, from the network, machine, application and people’s level. Draw graphs of these measurements, even if they aren’t drifting . You’ll be surprised by correlations you never expected.
“Make it ridiculously simple for any engineer to get anything they can count or time into a graph with almost no effort.” Ian Malpass
2 — Hypothesis
Once you’ve nailed your steady state, you can start making your hypothesis.

What if this recommendation engine stops?
What if this load balancer breaks?
What if caching fails?
What if latency increases by 300ms?
What if the master database stops?
Pick only one hypothesis of course, and don’t make it more complex than necessary. Start small.
I love starting with people (business) resiliency hypothesis first. Have you heard of the bus factor? The bus factor is a measurement of the risk resulting from knowledge not being shared among team members and is the minimum number of team members that have to suddenly disappear from a project before the project stalls due to lack of knowledgeable or competent personnel.
How many of you have technical experts on your teams that, if they were to get hit by a bus, it would be devastating for both the project and the team? I’ve had a few in the past!
Identify these people and run chaos experiments on them: for example, take their laptops and send them home for the day — and observe the often-chaotic results.
Make it everyone’s problem!
When doing the hypothesis, bring the entire team around the table — YES! Everyone — the product owner, the technical product manager, backend and frontend developers, designers, architects, etc. Everyone involved in one way or another with the product.
What I like to do the first time is ask everyone to write their own answer to the “What if …?” on a piece of paper, in private. What you’ll see is that most of the time, everyone will have a different hypothetical answer, and often, some of the team will not have thought about the hypothesis at all.
Stop there and discuss why some team members have a different understanding of how the product should behave during the “What if…?” Go back to the product specifications and make it clear what the expectations are for everyone in the team.
Take, for example, the Amazon.com retail site. What if the “Shop by Category” service fails to load on the main page?

Should you return a 404? Should you load parts of the page and let a blank box like in the below page?

Should the page gracefully degrade and, for example, collapse and hide the failure?

And that’s just on the UI side. What should happen on the backend? Should alerts be sent? Should the failing dependency continue to receive requests every time a user goes to the home page or should the backend circuit break the failing dependency?
One last thing, please don’t make a hypothesis that you know will break you! Make hypothesis on parts of the system you believe are resilient — after all, that’s the whole point of the experiment.
3 — Design and run the experiment
Pick one hypothesis
Scope your experiment
Identify the relevant metrics to measure
Notify the organization
Today, many people as well as principlesofchaos preach chaos engineering in production. While this should be an end goal, is it scary for most organizations and should really not be where anyone starts.
To me, chaos engineering isn’t only about breaking things in production — it’s a journey. A journey about learning by breaking things in a controlled environment — any environment — whether it’s your local dev, beta, staging, or prod, and through well-planned experiments in order to build confidence in your application to withstand turbulent conditions. “Build confidence” is key here as it will be the precursor to the cultural change that is required to run a successful chaos engineering or resiliency practice within your company.
Frankly, most teams will learn a LOT by breaking things in a non-production environment. Just try doing a simple docker stop database in your local environment and see if you can gracefully handle the use case. Chances are you can’t.
Start small, and slowly build confidence within your team and your organization. People will tell you “real production traffic is the only way to reliably capture the system behavior”. Listen, smile and keep doing what you’re doing — slowly. The worst thing you can do is to start chaos engineering in production and fail miserably. No one will trust you anymore and you can say bye-bye to the chaos monkeys.
Earn trust first. Show your organization and peers that you know what you’re doing. Be the firefighter, and learn about fire as much as possible before training with live fire. Earn your credentials. Remember “The Tortoise and the Hare” story: slow and steady always wins the race.
One of the most important things during the experiment phase is understanding the potential blast radius of the experiment and the failure you’re injecting — and minimize it. Ask yourself the following questions:
How many customers are affected?
What functionality is impaired?
Which locations are impacted?
Try to have an emergency stop button or a way to stop your experiment to get back to the normal steady state as fast as possible. I love conducting experiments using canary deployment which is a technique used to reduce the risk of failure when new versions of applications enter production, by gradually rolling out the change to a small subset of users and then slowly rolling it out to the entire infrastructure and making it available to everybody. I love canary deployment simply because it supports the principle of immutable infrastructure and it is fairly easy to stop the canary experiment.

Be careful with experiments that modify the application state (cache or databases) or that can’t be rolled back easily or at all.
Interestingly, Adrian Cockcroft told me that one of the reasons Netflix started using NoSQL databases was that there is no schema to change or rollback, so it’s much easier to incrementally update or fix individual data records — thus more chaos engineering friendly.
4 — Learn and verify
In order to learn and verify, you need to measure. As stated previously, invest in measuring everything! Then, quantify the results and always, always start with measuring the time to detect. I’ve lived several outages where the alerting system failed and customers or Twitter became the alarm … and trust me, you don’t want to end up in that situation — so use chaos experiments to test your monitoring and alerting systems as well.
Time to detect?
Time for notification? And escalation?
Time to public notification?
Time for graceful degradation to kick-in?
Time for self-healing?
Time to recovery — partial and full?
Time to all-clear and stable?
Remember that there’s no isolated cause of an accident. Large incidents always result from several smaller failures that add-up to create larger-scale events.
Do a postmortem for every experiment — every single one of them!
At AWS we invest a lot of time making sure every postmortem is a deep-dive on the issues found to understand the reason(s) why failure happened and to prevent a similar failure in the future. The output from the postmortem is called a Correction-of-Errors document, or COE. We use COE to learn from our mistakes, whether they’re flaws in technology, process, or even the organization. We use this mechanism to resolve root causes and drive continuous improvement.
The key to being successful in this process is being open and transparent about what went wrong. One of the most important guidelines for writing a good COE is to be blameless and avoid identifying individuals by name. This is often challenging in an environment that doesn’t encourage such behavior and that doesn’t embrace failure. Amazon uses a collection of Leadership Principles to encourage such behavior — for example, being self-critical, diving deep, insisting on the highest standards and ownership are key to the COE process and operational excellence in general.
There are five main sections in a COE document.
1 — What happened? (Timeline)
2 — What was the impact to our customers?
3 — Why did the error occur? (The 5 Why’s)
4 — What did you learn?
5 — And how will you prevent it from happening again in the future?
These questions are harder to answer than they appear because you really have to make sure every single unknown is answered carefully and precisely.
To make the COE mechanism a complete process, we have continuous inspection in the form of weekly operational metrics review meetings. There’s also an AWS-wide weekly metrics review meeting led by AWS’s senior technical leadership.
5 — Improve and fix it!
The most important lesson here is to prioritize fixing the findings of your chaos experiments over developing new features! Get upper management to enforce that process and buy into the idea that fixing current issues is more important than continuing the development of new features.
I once helped a customer identify critical resiliency issues from a chaos experiment — but due to sales pressure, the fix got deprioritized and pushed out in favor of a new, “very important” customer feature. Two weeks later, a 16h outage forced the company to implement fixes for the exact issues identified during the earlier chaos experiment — but at a much bigger cost.
The benefits of chaos engineering
The benefits are multiple, but I’ll outline two which I think are the most important:
First, chaos engineering help you uncover the unknowns in your system and fix them before they happen in production at 3am during the weekend — so, first, improved resiliency and sleep.
Second, a successful chaos engineering practice always generates a lot more changes than anticipated, and these are mostly cultural. Probably the most important of these changes is a natural evolution towards a “non-blaming” culture: the “Why did you do that?” turns into a “How can we avoid doing that in the future?” — resulting in happier and more efficient, empowered, engaged and successful teams. And that’s gold!
That’s all for this part folks. I hope you have enjoyed this Part 1. Please don’t hesitate to give me feedback, share your opinion, or simply clap your hands. In the next blog post, I’ll r̶e̶v̶i̶e̶w̶ ̶t̶h̶e̶ ̶t̶o̶o̶l̶s̶ ̶a̶n̶d̶ ̶t̶e̶c̶h̶n̶i̶q̶u̶e̶s̶ ̶u̶s̶e̶d̶ ̶t̶o̶ ̶i̶n̶j̶e̶c̶t̶ ̶f̶a̶i̶l̶u̶r̶e̶s̶ ̶i̶n̶t̶o̶ ̶s̶y̶s̶t̶e̶m̶s explain how to plan your first experiment. Until then, stay banana!
UPDATE:
Chaos Engineering — Part 2: Planning your first experiment
If you can’t wait for Part 2, following is a talk on practical chaos engineering that I did at NDC Oslo, in which I cover many of my favorite tools :)
Adrian
—
Subscribe to my stories here.
Join Medium for $5 — Access all of Medium + support me & others!