


Building resilience-focused organizations
The importance of culture, mechanisms, and tools

The importance of culture, mechanisms, and tools


“How do you build a resilience-focused organization?”
In this blog post, I aim to address this question and provide some insights into some of the strategies that I believe have proven effective for AWS.
In my view, building a resilience-focused organization requires three essential elements that are interrelated. First, cultivating the right culture is crucial. Second, having the right tools is essential. And third, establishing comprehensive mechanisms is vital. These principles are relevant to organizations of all sizes, whether they are large, medium, or small.
Before I begin, it’s important to note that the strategies I discuss are tailored to our specific organization and its unique culture. What has worked for us may not necessarily be applicable to every situation, so it’s crucial to exercise your own judgment.
Let’s begin by examining the first step: creating a Culture of Resilience.
Culture
Have you heard of Conway’s Law? It was named after Melvin Conway, who introduced it in 1967. Conway’s Law states:
“Organizations which design systems… are constrained to produce designs which are copies of the communication structures of these organizations.” M. Conways
In practice, it means that a system’s design is a copy of the organization’s communication structure.
When it comes to resilience, the most obvious effect of Conway’s Law is illustrated with the different interpretations of safety.
In his book, Safety-I and Safety-II, Hollnagel describes that really well.

He explains that Safety-I organizations focus on the things that go wrong: accidents, incidents, near misses. They believe safety can be achieved by first finding and then eliminating the causes of failures. In other words, they fear failure and avoid it at all costs.
Safety-II organizations, on the other hand, focus on resilience. They believe failure to be good, to be an opportunity for growth.
The fear of failure
Many organizations in the Safety-I bucket lack confidence in their IT services and fear failures. They often believe that failures are preventable because they believe IT services are predictable, and failures are caused by isolated changes.
These organizations often focus on maximizing the return on investment from their current IT services and resist changes. These have led to the development of robustness-centric risk management practices such as processes, rules, controls, change management — put in place to reduce the risk of failures. Frameworks such as ITIL are a good example of frameworks optimized for robustness.
These practices are called Risk Management Theater, a term coined by Jez Humble. They are based on the assumption that preventative controls on everyone will prevent anyone from making a mistake.
These are some of the practices robustness-centric organizations put in place to reduce the risk of failures.
The problem is that maximizing robustness often leaves organizations ill-equipped to deal with failure. When an organization optimizes for robustness, it will under-invest in non-functional requirements: monitoring, telemetry, infrastructure support, automation, and so on.
Worse, it will be considered acceptable because for Safety-I organizations, failures are expected to be rare.
These organizations believe complex systems are safe, except for the mistakes of unreliable people, an attitude Sidney Dekker calls the bad apple theory; When something bad happens, it must be the fault of someone.
Unfortunately, it is naive to think like that and this attitude and culture discourages learning, sharing, and collaboration.
The reality is that production environments are in perpetual state of failure. Because production systems often comprise hundreds of dependencies, there is a very high probability that at any given time, something somewhere is most likely failing.
“The complexity of these systems makes it impossible for them to run without multiple flaws being present” — Richard Cook - “How Complex Systems Fail”
A production environment is a collection of unpredictable interactions happening in unrepeatable conditions. It is a complex system in which the cause of an event can only be understood in retrospect, and thus embracing resilience is key.
What is Resilience?
In Resilience Engineering In Practice, the authors break down resilience using a conceptual model known as the Four Cornerstones of Resilience.

(1) Anticipating — Understand what to expect, imagine potential failures, and attempt to mitigate those in advance.
(2) Monitoring — Observe operational conditions and alert when faulty conditions occur.
(3) Responding — Understand what to do when failure happens.
(4) Learning — Understand why the failure happened, derive best practices and recommendations, and share them with the rest of the organization.
Simply put, resilience is the ability for a system to respond, absorb, adapt to, and eventually recover from unexpected conditions.
Resilience is a very intimate part of the Amazon culture. Werner Vogels, CTO of Amazon, famously said:
“Failures are a given, and everything will eventually fail over time.”
This focus on building a resilient organization has created a strong culture of ownership at Amazon, and ownership extends to operating software in production.
Amazon doesn’t believe in “throwing it over the wall”. Instead, we believe in “you build it, you own it”. That means that each service is owned and operated by a team who build, deploy, maintain, operate, and improve the service.
Developers get to directly see how their code works in production.
While many Safety-I organizations organize themselves into functional silos, separating operations and engineering, at Amazon we believe that a resilience-focused organizational model where all the functions live under one roof and are focused on a single customer need gets the best results. We call these 2-pizza teams. And these 2-pizza teams are responsible for the entire lifecycle of their product. But they aren’t responsible for building the tools.
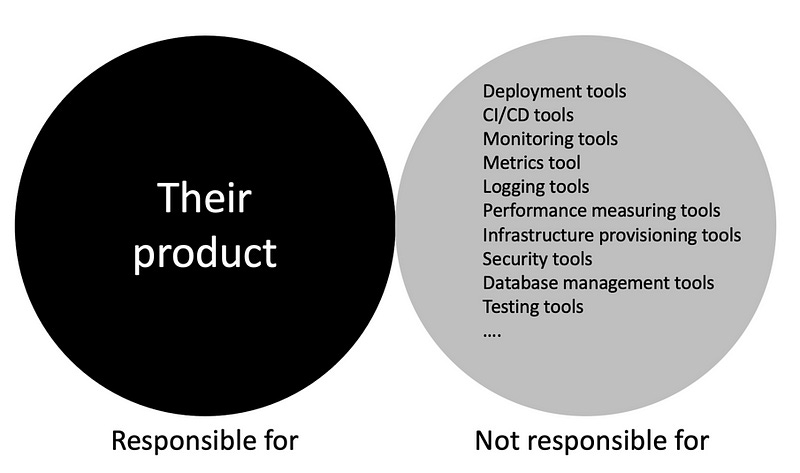
For that, Amazon has dedicated teams so that when we find issues in our tooling and fix them, everyone in the organization benefits.
One of the significant benefits of that distributed organization model is that these 2-pizza teams have the insights to immediately understand and address any issues or failures they encounter. It is hard to argue against the idea that being intimate with the code helps you understand the issue faster and thus recover faster.
This familiarity with the code is crucial for resilience because the ability to quickly recover from failures matters more than how often failures occur.
Time to recovery is more important than the frequency of failures because it directly correlates with a system’s resilience and overall performance. When failures inevitably occur (no system is ever 100% available), a quick recovery minimizes downtime and disruption, ensuring that the system remains reliable and available.
This focus on rapid recovery enhances user experience, reduces potential financial losses, and demonstrates the system’s ability to adapt in the presence of unexpected conditions.
Mechanisms
Now let’s talk about another very important aspect of resilience: Mechanisms.
To help you understand the importance of mechanisms, I first want to share a story from Jeff Bezos.
Several years ago, Jeff took part in customer connection training, and together with a very experienced customer-service (CS) representative, he took a phone call from a customer to respond to a complaint.
As soon as the CS representative pulled up the list of orders from that customer, she looked at Jeff and whispered that the customer was probably going to be returning one particular item on the list — a table — and added that the table in question was going to be damaged.
As you can imagine, Jeff was a little baffled by this prediction.
And indeed, the customer explained that she wanted to return the table because it was damaged.
After the phone call, Jeff asked the CS representative how she knew in advance that the table was going to be damaged. She answered:
“Oh! Those tables always come back, and they’re always damaged. They’re not packaged right, so the surface of the table always gets scratched.”
Jeff scratched his head, wondering how something so easy to avoid was happening.
After the training, like any CEO wanting to solve a problem, Jeff turned to the customer service leadership team. He asked them to do a better job and to make sure that the feedback loop between the customer service and retail department was closed.
Can you guess what happened?
Well, nothing happened.
Nothing happened because Jeff was asking for good intentions.
To understand how good intention works, think about the following. Do you wake up in the morning, go to work and tell yourself:
“Today, I’m going to do a terrible job!”
I guess no. Most of us want to do well. We have good intentions.
And so did everyone in the customer service department.
If good intentions don’t work, what does?
The answer is mechanisms. Mechanisms are a lot better at fixing recurring problems than good intentions.
And so Amazon went to borrow an idea that originally came from Toyota’s culture.
The Andon Cord
Toyota has had, for a long time now, cords along the assembly line that anyone can pull. Pull the cord, and it stops the production line (red arrow in the picture below).

Those cords — called Andon Cords — are often mistakenly identified as safety equipment. However, at Toyota, they’re a way to prevent any defect, no matter how small, from moving down the manufacturing line.
Any employee at Toyota is fully empowered — and expected — to pull the cord if they see or become aware of any defect. Immediately after the Andon Cord is pulled, a team leader will personally go see the issue at the problematic workstation and thank the operator for stopping a defect from going down the manufacturing line.
That’s a real mechanism — empowering everyone in the company to stop defects and fix them before they reach customers.
Back to Amazon
Amazon took that simple but powerful idea and built the Andon customer service, a tool that lets any customer service representative “stop the line,” which means removing any product on the Amazon retail website in minutes until the defect gets fixed.
It’s still up and running today and has been very successful.
Following is an example of the Andon Cord at work. The item is under review because an Andon Cord has been pulled.
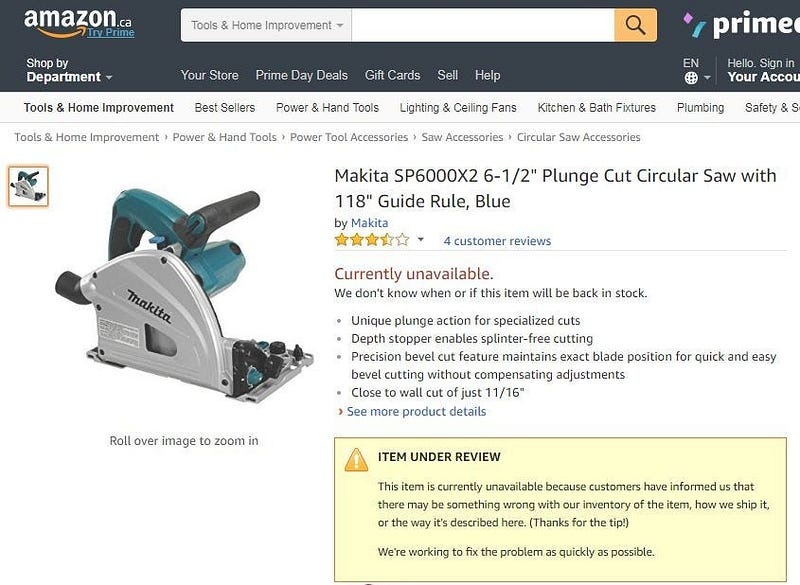
Amazon has built multiple versions of the Andon mechanism — where rather than relying on good intention, we rely on a strong mechanism to do the right thing.
Mechanisms are a lot better at fixing recurring problems than good intentions, and that is true for resilience.
Rather than let resilience be driven by good intentions, we have relied on strong mechanisms to make sure resilience is not a victim of good intention.
Fault Isolation Boundaries
Arguably, the most important of these mechanisms is something called Fault Isolation Boundaries.
The main purpose of these boundaries is to limit the effect of a failure within a system to a limited number of components. Components outside of the boundary are unaffected by the failure.
Fault Isolation Boundaries play a crucial role in ensuring resilience. Using multiple fault isolated boundaries, you can control the impact on your workload. It has additional benefits too, like the ability to use that boundary as a scaling unit. It also greatly simplifies testing and management of the resources within a particular boundary.
AWS uses Regions, Availability Zones, and separates Control and Data Planes to prevent widespread failures and Cells further minimize disruptions by dividing services into smaller units.

AWS Regions and Availability Zones
The most familiar boundaries used in AWS are Regions and Availability Zones. At the time of writing this post, AWS operates 102 Availability Zones within 32 Regions around the world.

An Availability Zone is one or more discrete data centers with independent and redundant power infrastructure, networking, and connectivity in an AWS Region.
Availability Zones in a Region are meaningfully distant from each other, up to 100 km, to prevent correlated failures, but close enough to use synchronous replication with single-digit millisecond latency. They are designed not to be simultaneously impacted by a shared fate scenario like utility power, water disruption, fiber isolation, earthquakes, fires, tornadoes, or floods.
Common points of failure, like generators and cooling equipment, are not shared across Availability Zones and are designed to be supplied by independent power substations. All Availability Zones in a Region are interconnected with high-bandwidth, low-latency networking, over fully redundant, dedicated metro fiber. Each Availability Zone in a Region connects to the internet through two transit centers where AWS peers with multiple tier-1 internet providers.
These features provide strong isolation of Availability Zones from each other, which we refer to as Availability Zone Independence (AZI).
It is also worth mentioning that when we deploy updates to our services, we typically deploy one AZ (per region) at a time, and by waves, deploy to more regions progressively to limit the blast radius of potential failures brought by the new version of the software.
Each Region consists of multiple independent and physically separate Availability Zones within a geographic area. All Regions currently have three or more Availability Zones. Regions themselves are isolated and independent from other Regions with a few exceptions. This separation between Regions limits service failures, when they occur, to a single Region.
Control and Data Planes
We also like to separate the access to the services and its supporting infrastructure in terms of the service Data and Control Planes.
Control plane consists of the customer functions for setting up the environment. Data plane consists of the customer functions for using the environment to derive real-time value from the service.

Data plane components typically sit on the request path, and control plane components help that data plane do its work.
Why does this distinction matter?
For reliability purposes, we attempt to decouple control and data planes in their architecture so that one plane’s outage does not take down the other plane.
Traditionally, the data plane’s reliability has been prioritized over the control plane’s, although both should be as resilient as possible. Data planes are intentionally less complicated, with fewer moving parts compared to control planes, which usually implement a complex system of workflows, business logic, and databases. This makes failure events statistically less likely to occur in the data plane versus the control plane.
While both the data and control plane contribute to the overall operation and success of the service, AWS considers them to be distinct components. This separation has both performance and availability benefits.
One important aspect critical to this distinction is that during an outage, we avoid using the control plane for recovery. That’s because they are more complicated and have more dependencies, and during an outage, control planes are more likely to be impaired.
Cells
Another important fault isolation boundary used at AWS is something called cells.
Cells are multiple instantiations of a service that are isolated from each other; these service structures are invisible to customers. Each customer gets assigned a cell or a set of cells. In a cell-based architecture, resources and requests are partitioned into cells, which are capped in size. This design minimizes the chance that a disruption in one cell — for example, one subset of customers — would disrupt other cells.
By reducing the blast radius of a given failure within a service based on cells, overall availability increases and continuity of service remains. For a typical multi-availability zone service architecture, a cell would comprise the overall regional architecture. Now take regional design — that’s our cell.
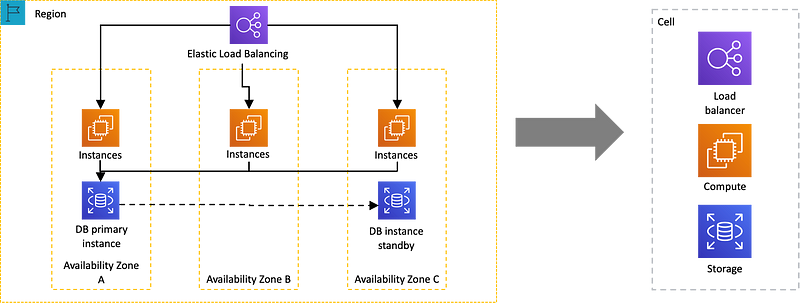
We then place our cells behind a thin routing layer like illustrated here.

To learn more about these techniques, I strongly recommend reading that post from Colm MacCárthaigh, Distinguished Engineer at AWS.
Static stability
Another important resilience mechanism we extensively use at AWS is static stability.
The term static stability describes the capability for a system to keep its original steady-state (or behavior) even when subjected to disruptive events without having to make any changes.
Though an oversimplification, consider an airplane equipped with four engines. It can maintain its flight, almost as if nothing were wrong, even when one or two of its engines are temporarily shut down. No immediate action is required; the aircraft can rely on the remaining engines to sustain it’s course. In this configuration, the airplane demonstrates static stability.
An example of static stability can be found in Amazon EC2. When an EC2 instance is launched, it remains as available as a physical server in a data center. It doesn’t rely on control plane APIs to maintain operation or to recover after a reboot. This characteristic extends to other AWS resources, including VPCs, S3 buckets and objects, and EBS volumes.
Static stability and fault isolation boundaries discussed previously are closely related. Boundaries are in fact fundamental to achieving and maintaining stability in complex systems because they limit the impact of failures within a clearly defined scope, preventing wide failure propagation.
It’s worth noting that control planes tend to experience a higher likelihood of failure compared to data planes because they typically involve more complex workflows and business logic, making them more prone to issues. While the data plane typically relies on data from the control plane, it retains its operational state and continues functioning, even in the event of a control plane issue. For that to happen, data plane access to resources should have no dependency on the control plane. This makes AWS data planes statically stable to an impairment in the control plane.
You can read more on how static stability applies to the Lambda service itself in that blog post. In lambda’s cases, static stability is built around availability zones.
Tools
Now, let’s talk a bit about tools. There are, of course, a broad set of tools needed to build and operate a resilient cloud.
The essential categories are listed here:
Code review
Code profiler
Test Automation
Configuration Management
Software Deployment
Monitoring and Visualization
Fault Injection
Load Testing
Reporting
Change Management
Incident Management
Trouble Ticketing
Security Auditing
Forecasting and Planning
While all of them are important, building resilient systems always starts with reviewing and profiling your application’s code.
Code quality is critical, as it impacts how safe, secure, and reliable your application is.
It is the foundation on top of which many businesses are built and thus continuously delivering high quality code is critical for resilience.
Code is considered good if it:
1 — Does what it should.
2 — Follows a consistent style.
3 — Is easy to understand.
4 — Is well-documented.
5 — Can be tested.
Code reviews have plenty of benefits: improving code quality, locating defects, mentoring newer engineers, lowering complexity, etc.
While human-based code review processes are mandatory, tools have become essentials to assist reviews and suggest improvements. Tools, unlike humans, don’t respond to stress or fatigue and are consistent with their judgments.
Amazon’s internal teams have used code reviewers and profilers on more than 30,000 production applications.
From 2017 to 2018, while working on improving its resilience for the biggest shopping day of the year, Prime Day, Amazon also realized a 325% efficiency increase in CPU utilization and lowered costs by 39% by using ML-powered code reviewers and code profilers [source].
That’s tens of millions of dollars in savings on compute and infrastructure costs — dollars that can be invested somewhere else.
That tool that Amazon.com used is publicly accessible to anyone using the AWS Console, and it is called Amazon CodeGuru.
Code reviews are essential at each stage of the application life cycle — both during development and once the application is up and running.

CodeGuru is powered by machine learning and provides recommendations for improving code quality and identifying expensive lines of code. It scans for critical issues, finds hard-to-find bugs, and also recommends how to remediate them before they become outages in production.
By integrating continuous code reviews and code profiling into your development pipeline, you will significantly improve code quality and, thus, continuously improve your applications’ resilience.
Automation
Arguably, the most important aspect of building resilient software system is automation. It effectively reduces human error, speeds up repetitive tasks, and guarantees consistent configurations. Through the automation of deployment, monitoring, and scaling processes, software systems can quickly adapt to evolving conditions and recover from failures more efficiently.
In order to automate build commands, Amazon created a centralized, hosted build system called Brazil. The main functions of Brazil are compiling, versioning, and dependency management, with a focus on build reproducibility. Brazil executes a series of commands to generate artifacts that can be stored and then deployed. To deploy these artifacts, Apollo was created.
Apollo was developed to reliably deploy a specified set of software artifacts across a fleet of instances. Developers define the process for a single host, and Apollo coordinates that update across the entire fleet of hosts.
Developers could simply push-deploy their application to development, staging, and production environments. No logging into the host, no commands to run. These automated deployments removed the bottleneck and enabled teams to innovate and deliver new features for customers rapidly. However, automated deployments can’t solve everything. Deployments are, in fact, part of a bigger picture. They’re part of a workflow that starts the instant a developer commits code to the repository and ends when that change is successfully running in production.
Pipelines model that workflow and the path that code takes from check-in to production. Pipelines are a continuous deployment system that allows developers to create a fully automated deployment — from the moment code is checked in and passes its tests — to production, without manual intervention. Of course, not everything can be fully automated. Still, Pipelines will automate the steps the team is comfortable with, and most importantly, codify the steps required between checking in code and having it running in production. Pipelines are also where the verification steps happen, whether it’s testing, compliance verification, security reviews, auditing, or explicit approvals.
Brazil, Apollo, and Pipelines brought a lot of goodness to our organization and to our customers, but they also brought a lot of software changes, and by 2018, we were doing hundreds of millions of deployments a year.
More importantly, while speeding up software delivery, the broad adoption of these tools reduced the risk of deployment failures, as these tools drove consistency, standardization, and simplification of the release processes. Indeed, the development of these tools resulted in fewer defects being launched into production — and happier customers.
That’s the essence of resilience.
If you want to learn more about Brazil, Apollo, and Pipelines, read Werner Vogels’ blog post here.
GameDays
And finally, addressing resilience would not be possible without talking about GameDays.
In the early 2000s, Jesse Robbins, whose official title was Master of Disaster at Amazon, created and led a program called GameDay, a program inspired by his experience training as a firefighter. GameDay was designed to test, train and prepare Amazon systems, software, and people to respond to a disaster.
Just as firefighters train to build an intuition to fight live fires, Jesse’s goal was to help his team build an intuition against live, large-scale catastrophic failures.
GameDay was designed to increase Amazon retail website resiliency by purposely injecting failures, and load, into critical systems.
Initially, GameDay started with a series of company-wide announcements that an exercise — sometimes as large as a full-scale data-center destruction — was going to happen. Little detail about the exercise was given and the team had just a few months to prepare for it. The focal point was to make sure regional single points of failure would be tackled and eliminated.
During these exercises, tools and process such as monitoring, alerts and on-calls were used to test and expose flows in the standard incident-response capabilities. GameDay became really good at exposing classic architectural defects but would sometimes also expose what’s called “latent defects” — problems that appear only because of the failure you’ve triggered. For example, incident management systems critical to the recovery process fail due to unknown dependencies triggered by the fault injected.
As the company grew, so did the theoretical blast radius of GameDay, and these exercises evolved into different compartmentalized experiments. All these have a common goal however, exercise failure modes through chaos engineering or load testing.
Chaos engineering — what is it and why is it important?
Chaos engineering is a systematic process that involves deliberately subjecting an application to disruptive events in a risk mitigated way, closely monitoring its response, and implementing necessary improvements. Its purpose is to validate or challenge assumptions about the application’s ability to handle such disruptions. Instead of leaving these events to chance, chaos engineering empowers engineers to orchestrate controlled experiments in a controlled environment, typically during periods of low traffic and with readily available engineering support for effective mitigation.
The foundation of chaos engineering lies in following a well-defined and scientific approach. It begins with understanding the normal operating conditions, known as the steady-state, of the system under consideration. From there, a hypothesis is formulated, an experiment is designed and executed, often involving the deliberate injection of faults or disruptions. The results of the experiment are then carefully verified and analyzed, enabling valuable learning that can be leveraged to enhance the system’s resilience.

While chaos engineering primarily aims to improve the resilience of an application, its benefits extend beyond that aspect alone. It serves as a valuable tool for improving various facets of the application, including its performance, as well as uncovering latent issues that might have remained hidden otherwise. Additionally, chaos engineering helps reveal deficiencies in monitoring, observability, and alarm systems, allowing for their refinement. It also contributes to reducing recovery time and enhancing operational skills. Chaos engineering accelerates the adoption of best practices and cultivates a mindset of continuous improvement. Ultimately, it enables teams to build and hone their operational skills through regular practice and repetition.
Here is how I usually like to put it:
Chaos engineering is a compression algorithm for experience.
Load testing
Load testing is the process of testing the performance of an application by subjecting it to various type of load levels and traffic characteristics. Load testing is a critical aspect of software development that serves several crucial purposes in ensuring the reliability and performance of applications. There are 3 main types of load tests relevant to resilience: performance, peak, and stress. Performance load testing is performed on a system to determine its performance characteristics and is designed to provide an indication of how systems behave under normal traffic conditions. Peak load testing, on the other hand, defines the maximum amount of work a system is capable of sustaining without significant degradation of the customer experience. Finally, stress load testing evaluates how systems function at their limits, up until their breaking points. The type of load test depend on the specific objectives and requirements of the test.
Using load with chaos engineering
While load testing and conducting chaos experiments are both important in their own rights, looking at them in isolation from one another can make teams believe that systems will behave well under the tested conditions.
However, like I mentioned earlier, systems are complex and their distributed nature often means that complex interactions between sub-systems will happen under extreme conditions.
For example, systems failures often occur in systems with an uncontrolled source of load where a trigger causes the system to enter a bad state that persists even when the trigger is removed. These are called metastable failures and have already caused widespread outages in the industry.
Paradoxically, the root causes of these metastable failures are often features meant to improve the resilience, performance, or reliability of the system. Potential triggers for these metastable failures include retries, caching, slow error handling paths, and emergent properties of load-balancing algorithms. There are many more triggers that can lead to metastable failure state, thus combining load testing with other form of testing, e.g., chaos engineering, helps reproduce the extreme conditions by which these triggers surface.
A good analogy for the importance of combining load testing with fault injection (or any other form of testing) is that of wind tunnels in car manufacturing and the story of the KIA Telluride car.
A wind tunnel typically comprises a test section where a vehicle can be mounted and viewed whilst air is either blown or more usually sucked over it by a fan or number of fans. Data can be gathered from a balance on which the vehicle is mounted and visualization techniques such as adding smoke trails to the airflow can be used to gain an understanding of how certain geometric features affect its aerodynamic. In fact, wind tunnels are really great for gathering and optimizing the aerodynamic performance of cars.
While the performance of cars is important, in real conditions, one could argue that robustness or resilience are more important (at least for passengers). It turns out that KIA Telluride clients have been reporting that windshields for the KIA Telluride appear to be faulty, soft, or defective. These complaints state that the windshield cracked while driving either completely spontaneously or from a small rock.
After days of wind tunnel performance optimization, it turns out that a small rock thrown at high speed on the windscreen may totally break it. Throwing a small stone on the windscreen, without a 60MPH wind does nothing. 60MPH wind alone does nothing. But combined, the two stressors expose a big flow in the design of the windscreen.
It is the same with software testing. Combining load testing with chaos engineering helps reproduce the extreme conditions of real-world environments.
One final thing to remember is that implementing resilience across an organization takes time. Don’t lose patience and trust the process. There is no secret sauce. The real quality of how to achieve high resilience is based on habits, paying attention to details, being paranoid about what could go wrong, and consistently striving for improvements.
Resilience is not an act but a habit.
Thanks.